Effect-based Multi-viewer Caching for Cloud-native Rendering
1 Summary
本文基于object-space/texture-space shading管线,提出一种面向multi-viewers的云渲染的cache系统设计。对于effect中与视角无关的部分,通过转换为texture-space下的渲染任务,并且设计effect-based cache系统,使得不同viewers共享同一份effect中间数据。提出的effect-based cache系统共包含定义在物体表面的On-Surface Cache(OSC)与定义在grid上的World-Space Cache(WSC)两种策略,统一使用hash table的形式进行存储管理,但二者具有不同的hash key设计,包含实际数据的cache entry由具体的effect定义。作者为两种cache策略分别给出相应的具体effect应用,同时提出通过为不同的effect使用不同的bias配置来为低频effect选择低分辨率,减少内存开销。
2 Background
3 Pipeline设计
管线设计如图 Fig-1,首先为每个viewer执行visibility pass来决定那些cache entries会被使用到;然后对所有viewers的cache request进行整合更新,这一步可以执行在不同的GPU上;之后viewers再通过采样cache来着色帧;最后是后处理,将生成的图像插入到output stream。

想要被多个viewer复用,被cache的计算只能是视角无关的,同时作者提出基于effect的cache设计,可以为不同类型的渲染计算进行调整。经过对现代游戏引擎中的效果分析,作者提出两种类型的cache:on-surface cache,共享表面点上的计算;world-space cache,共享世界空间数据。
3.1 On-Surface Caches
On-Surface Cache(OSC)采用类似于[2]的管线。首先预处理阶段需要为mesh生成唯一表示的纹理空间。作者通过将一定数量的相连接的面片划分成island单位,每个island有独立的texture space,可以生成triangle lookup texture,即每个texel的triangle id。
对于cache texture的实现,尽管目前硬件支持virtual texture,但64KB的page大小对于本系统过大,因此作者采用软件实现的cache系统。为了更好的spatio-temporal重用,作者设计了用于访问所有virtual textures的单个hash map,hash map中存储的是指向cache entry(实际数据)的hash entry。一个page table/hash map entry(页表项)由如下部分组成:
- island index:32bit,用来标识island,island下是独立的texture space
- resolution:4bit,应该是mipmap level
- texel block coordinates:2x12bit,island下的8x8 texel block的纹理坐标。
因此可以最多表示 32kx32k的纹理空间($2^{12}*8=2^{15}=32\mathrm{k}$)
本文采用的cache entry大小为8x8 texel block,texel的实际大小由具体effect定义。
应该需要实现GPU上的hash map,键为 hash entry,值为指向cache entry的索引。:exclamation:
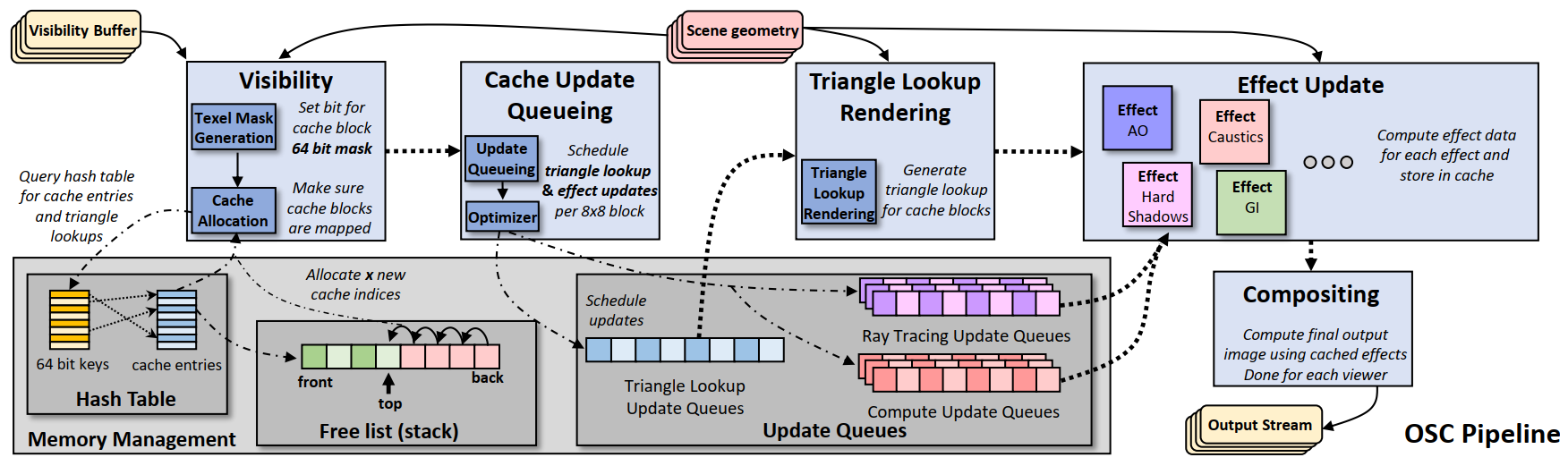
OSC pipeline主要由如图Fig-2中的五个阶段组成:
- Visibility:决定哪些cache entity会被用到以及去重cache request
- Cache Update Queuing:填充着色任务队列
- Triangle Lookup Rendering:
- Effect Update:cache更新
- Compositing:整合cache数据以及剩余的渲染计算生成最终渲染结果
3.1.1 Visibility
为每个viewer执行visibility pass生成所请求的cache entry,此外可以根据屏幕空间梯度以及每个effect的先验知识来调整cache entry的bias,提高目标mip level。例如空间低频的effect可以渲染的目标分辨率更低。
不是很清楚mip level如何工作的:question: 似乎是降低的是texture space的分辨率,例如level 0的分辨率32kx32k,level 1的分辨率则为16kx16k。
unbiased情况是通过屏幕空间梯度计算的mip level达到pixel与texel一一对应;biased情况是手动为某些低频effect增大mip level,多个pixel对应一个texel。
为每个texel block配置一个64bit mask,来标识block内哪些texel需要更新。对于每个surface point可能需要1、4、8个texel blocks,分别用于point、bilinear、trilinear采样。
虽然cache的最小单位是 8x8 texel block,但effect发起的应该是以像素为单位的请求,通过上面的bias来对应到具体的texel block的texel上。那么只有当shading point位于block边界上时,才会需要更多block用来做插值。
对于来自shading point的请求,先查询hash table确定所请求cache entry是否已经map,如果没有map,则map一个empty block。然后设置texel mask的对应位。texel mask会在每帧重置。通过这种方式,可以优雅去除重复请求。
基于virtual texture的hash table实现本身只是个数组,其查询过程需要从头到尾遍历。hash table的键值对,键为virtual texture的采用坐标、值为关联的texel block索引,该索引指向一块内存,由后面的memory manager管理。不同的effect应该指向不同的内存。
3.1.2 Cache Update Queuing
本阶段对visibility阶段生成的cache entry创建更新请求。为每个效果创建一个cache update queue,用于存储texel block的更新请求。生成update request可以通过遍历所有 page-table entries 或者使用 texel mask操作来确定需要更新的texel block。
个人理解:应该是通过遍历hash map中的所有条目,检查每条是否关联了实际了texel block,如果关联了则表示需要更新。或者是,texel mask是否全为0。那么所谓的cache update queue存储的是什么呢?指向hash map中条目的索引?:question:
为了应对一些情况,作者还在此阶段提出了三点优化。
在不同的视角下,同一cache位置可能会被多种不同分辨率使用到,例如trilinear filter。对于某些开销大的effect,相比于为同一着色点执行不同分辨率下的计算,从更高分辨率进行重采样可能更优。因此,为了实现此策略,新增一个resampling queue。在添加一个texel到update queue之前,是否已经存在同位置更高分辨率的更新。如果有,则将该texel以及其对应的重采样候选texel组成一个重采样操作,加入resampling queue中。
这里的重采样候选texel应该根据实际的重采样过程来确定。假设是mipmap,那么一个texel则需要4个更高分辨率的候选texel
不同effect的更新频率也不一定相同。有些effect不需要每帧更新,例如AO与DDGI达到收敛后,基本不再改变。这种效果的更新频率也可以用来控制cache update queuing
云渲染场景下,面对很多viewers时,可以将这些分配到不同的GPU上。这会导致同一个effect在不同GPU上都有一个cache update queuing。
3.1.3 Memory Management
前述过程中的数据结构中都不包含实际的texel block数据,而是指向texel block的内存索引。texel的具体大小与effect相关,因为cache的计算更多是中间结果,因此很可能不是常规的texel格式。本系统为不同texel大小预分配一定大小的buffer,并划分成block,然后cache update操作只引用指向这些block的索引。在启动阶段,使用一个栈(free list)来管理这些buffer block索引。
在执行过程中,避免内存不足,还需要能够将hash table中关联的block indices动态释放,放回free list。这个过程可以使用一个额外的compute shader完成,避免同时发生插入与删除。block的访问时间越近,意味着其包含的数据越容易被使用到,因此可以使用访问时间来指导unmap操作。为此,根据空闲block与新请求数量之间的比值来调整一个动态阈值,回收该阈值数量的最久未访问的block。
3.1.4 Triangle lookup rendering
在cache update的计算过程中,需要从cache texel对应到surface location,获取该位置处三角形的插值属性。这里需要用到triangle lookup textures,用来记录每个像素的triangle id。在texel shading管线中,该texture使用预计算得到,但这样无法支持动态场景以及内存开销较大,难以实际应用。
作者选择通过一个indirect rasterization管线实时生成triangle lookup texture。同时将过程抽象为一个effect,对其应用effect的内存管理机制。不同的是,triangle lookup “effect” 会被其他effect使用到,而且同一island的不同instance可以复用。此外,对于请求的cache block,虽然可以知道属于哪个island,但无法确定属于哪个三角形。因此选择将整个island送入indirect rasterization管线。由于island最多有256个三角形,同时triangle lookup不会频繁更新,因此这个阶段还算高效。
如何得到渲染需要的gbuffer数据?
每个view的visibility pass生成的visibility buffer得到的是屏幕像素的visibility信息,这在cache的texture space下并不连续。例如,即使8x8的texel block完全位于一个三角形内,也可能有部分texel没有visibility数据。想要在cache space下生成visibility信息,可以是:
view的visibility buffer得到命中的cache entry
为cache entry的每个texel遍历其所属island的每个三角形,判断texel属于哪个三角形。
判断过程使用 texel 的uv与三角形顶点的uv,还需要对未找到所属三角形的 texel 应用保守光栅化技术
3.1.5 Geometric LOD support
对于LOD的支持,可以选择将几何的不同LOD作为不同的island,但这会导致同一几何的不同LOD的cache完全独立,无法共享。另一种做法是不同LOD仍然使用同一连续UV空间,这样不同LOD的cache也能复用。这样的连续UV空间生成可以通过在生成几何LOD过程中,对顶点的简化同样应用到island uv上。
3.1.6 Thoughts
所有effect的cache entry的确定都是统一的,应该都是屏幕像素的texture coord(hash key)来确定。只是不同的effect可以调整其mipmap的bias。
那这个bias似乎只能提前预设好。因为visibility pass就会生成hash table的条目,已经确定texture space坐标了。
hash table的实现:vritual texture vs. 哈希实现
hash键的设计可以唯一索引virtual texture space的一个texel block。键的设计如下:
- island index:32bit,用来标识island,island下是独立的texture space
- resolution:4bit,应该是mipmap level
- texel block coordinates:2x12bit,(x, y)
按照上下文理解,hash table应该是基于virtual texture原理实现的,但并不是直接使用现有virtual texture的技术。
一共有 $2^{32}=2^{16}\times 2^{16}$ 个 island,每个island空间为 $2^{12} \times 2^{12}$,单位为 8x8 texel block。再加上mipmap,那么整个virtual texture space总大小为
$$
\begin{align}
& (2^{16} \cdot 2^{12} \cdot 2) \times (2^{16} \cdot 2^{12} \cdot 2) \
=& 2^{29} \times 2^{29}
\end{align}
$$
可以看出,这是一个用于表示整个场景的非常庞大的virtual texture space。相当于使用了非常庞大的空间实现一个完全无碰撞的hash。但实际一个viewer使用到的是很少一部分。- 如果是直接使用VT的做法,那么cache entry则使用physical texture保存。而texture的格式是有限制的,灵活性受限
- 文中描述的是VT的原理,但存储使用自定义的buffer进行,SSBO可以自定义结构体。
从后续“memory requirement”部分来看,本文采用的应该是hash table的实现,但没有给出具体的hash设计。
因此可以考虑实现一个高效的GPU上的hash table,可以避免virtual texture的开销(经过virtual texture的间接寻址过程),但同样会带来hash碰撞时的线性查找过程,以及hash table的大小难以确定,最大为每个viewer都是不重叠的情况。具体到底哪个更高效未知。
对于trilinear filter,文中提出之前的工作要么是不支持硬件加速,要么会引入1-pixel border。但文中的cache也一样不支持硬件加速的trilinear filter,而是使用重采样软件计算的。
memory management的实现:SSBO vs. texture
- SSBO 可以自定义内部数据格式
- texture只能使用rgba格式
3.2 World-Space Caches
WSC 是基于世界空间grid的cache。基于grid的effect数据大小差距较大,例如,一个probe会存储 8x8 个样本,而volume shadow只有1个float。因此cache entry大小的选择,与OSC选择固定的8x8 texel block不同,probe选择1x1x1 bricks更优,而volume shadow选择4x4x4 bricks更优。grid下的cache entry使用**world-grid index(WGI)**关联:对于1x1x1 bricks,可直接采用其世界坐标关;对于4x4x4 bricks,使用其中心坐标。此外,还必须保证grid是静态的,虽然可以根据相机的移动而出现与消失,但不能根据相机的移动而移动。
在多层级grid情况下,对于不同cache entry大小,可能不需要完整的octree结构。例如 4x4x4 bricks,这个对应了coarser level的一个grid,可以跳过一个level。而 1x1x1 brick 则需要每层级都需要。
WSC的管线与OCS类似:visibility确定需要的WGIs,再经过cache update queuing来调度更新cache entry。cache entry的分配同样使用一个hash map,而更新过程不再需要triangle lookup。
3.2.1 Hash Table
使用64bit整数的WGI作为键,其描述三个维度的grid坐标、以及层级level。每个维度使用21bits,可以描述两百万grids。而纵向维度往往范围较小,需要更小的分辨率,因此可以节省几个bits存放level。
对于非常大的场景,WGI满足不了分辨率,可以采用分块执行。
3.2.2 Lookup
与OSC不同,WSC的同一cache可能会被同一viewer多次查询。例如,一块像素采样周围的light probe采样到同一批probe。这会导致对同一个WGI进行多次hashing,这会重复访问hash map。
在面对一个hash key时,只能从头遍历hash map。如果存在该key,则得到关联cache entry。如果不存在,则会关联一个空的cache entry。因为本文基于virtual texture的hash map并非真正的hash map,其查找过程只能是遍历。:exclamation:
本文提出为每个viewer建立一个local lookup table,用来保存相机周围的cache entries,而对于其他位置仍然走hashing 流程。
local lookup table应该是根据grid坐标得到一个索引,可以直接访问得到其中cache entry。而不需要从头遍历。
3.2.3 Coherence
为了提高coherence,可以对cache update queue进行部分排序,同一viewer连续排放。
3.2.4 Effect Examples
Light probe、volumetric fog、volume shadow
3.3 Effects
作者列举了一些效果实现的示例
3.3.1 Hard Shadows
硬阴影只需要记录着色点到光源的可见性,cache在OSC。每个texel使用 2 Bytes记录16根shadow rays。
3.3.2 Ambient Occlusion
AO缓存在OSC,具有时序累积过程。每个texel共 4 Bytes:记录16-bit AO值,以及16-bit 样本数量(最大样本数量64)。
3.3.3 Indirect Diffuse Illumination
3.3.4 Reseroir Sampling
3.4 Cloud Setup
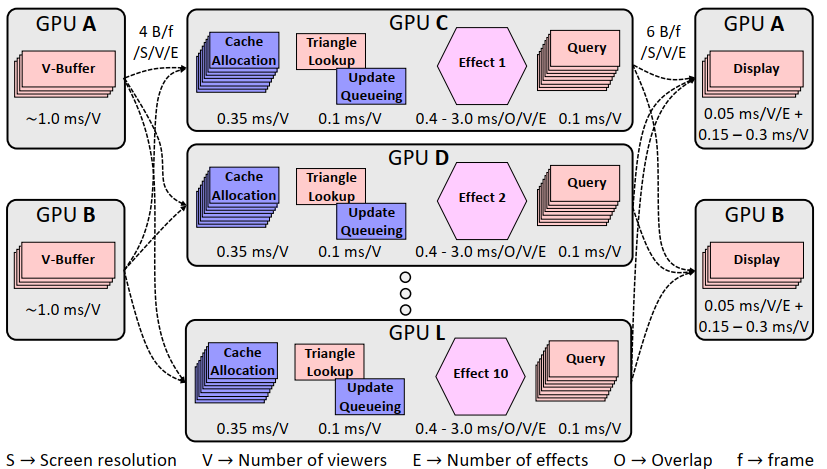
在分布式云渲染下,viewer GPUs发送cache request(V-buffer)到每个effect GPU,待effect GPU更新完effect cache后,再由 viewer GPUs 合成最终画面。
4 Evaluation
4.1 Memory requirements
每个texel block具有 8x8 texels,effect定义具体的texel大小,如3.3节。texel block的内存回收策略采用:当经过一定帧,没有被访问到后的texel block返回free list。
对于比较远或者比较小的物体,有可能对应的mip层级分辨率不足8x8或者texel block只有一个texel命中,此时会导致存储利用率降低。因此对于bias为2的版本,理论上存储开销为unbiased版本的1/16,但实际上只有 1.5~3 倍的减少。对于texel的更新数量能达到理论上的减少,因为有texel mask。
除了meta data(texel block的访问时间)外,内存管理还会引入额外的存储开销:
- memory allocation:每个hash table entry使用键值对(64bit键,32bit texel block index)。为了保证hash table的性能,hash table的容量选择150%的block总数,不高于75%的填充率。
- work queues:每项表示一个要执行的texel block,采用16 bytes 键值对
Reference
[1] Alexander Weinrauch. 2023. Effect-based Multi-viewer Caching for Cloud-native Rendering. siggraph (2023).
[2] K. E. Hillesland and J. C. Yang. 2016. Texel Shading. In Proceedings of the 37th Annual Conference of the European Association for Computer Graphics: Short Papers (Lisbon, Portugal) (EG ’16). Eurographics Association, Goslar, DEU, 73–76.