Scene Graph and Draw Call Grouping Strategy
Summary
本文介绍了表示场景的 Scene Graph ,以及场景加载过程。基于 Scene Graph 组织 draw call 的策略。
Scene Graph
Scene Graph 表示场景中物体的层级结构,是场景物体的组织形式。在本渲染器中,Scene Graph 主要由表示层级结构的基类UltraNode与组织场景物体的基类SceneObject组成。
1. 场景层级结构
UltraNode的子类SceneNode构建场景中的树形层级结构中的节点。除了表示层级结构,节点主要功能之一是支持变换,其管理的变换信息(旋转、平移、缩放)有:
- 相对于父节点坐标系的局部变换,对应成员有
mRelativePos、mRelativeRot、mRelativeScale - 相对于根节点坐标系的世界变换,对应成员有
mStackToRootPos、mStackToRootRot、mStackToRootScale以及将旋转、平移、缩放组合一起的变换矩阵mStackToRootTransform
变换的更新逻辑:节点提供变换接口,如 translate、rotate、scale 等,这些接口都提供参数来表示此次变换相对于哪个坐标系,最后都会改变局部变换信息。下面以 rotate 为例说明,假设旋转参数 rot,相对坐标系为 relative:
relative 是局部坐标系:mRelativeRot 是从 local 到 parent 的四元数旋转,因此先在 local space 应用 rot,有
1
mRelativeRot *= rotrelative 是父节点坐标系:因此先应用 mRelativeRot (local 到 parent),有
1
mRelativeRot = rot * mRelativeRot;relative 是世界坐标系:因此先应用 local 到 world 的变换,再应用 rot,再 world 到 local 的变换,有
1
mRelativeRot = mRelativeRot * glm::inverse(localToWorldRot) * rot * localToWorldRot;
世界变换相关成员的更新在其对应 GetXxx 函数中,如果检测到局部变换发生变化或者父节点局部变换发生变化时进行重新计算。
2. 场景物体的组织
SceneObject 的子类组织场景中的物体,如 mesh、光源、相机等。SceneObject 需要将物体 attach 到场景的节点中才会被渲染。目前实现的有组织 mesh 数据的 MeshEntity,表示投影相机的 FrustumObject。
MeshEntity:该类构建一个模型数据,由继承自 RenderableInterface 的 PrimitiveEntity 基本单元组成,表示使用一种材质的子 mesh。在场景加载过程中划分成 PrimitiveEntity,在渲染时通过 SceneManager 收集。
FrustumObject:相机的父类,一共有 Orthogonal 和 Perspective 两种相机。其包含了投影变换的信息,而相机的旋转、平移、缩放等信息由其 attach 到的场景节点表示,注意相机的 view transform 表示从世界到相机空间的变换,而其 attach 到的节点的世界变换为从 local 到世界的变换,local 即相机空间,因此求逆得到 view transform。相机实现了两种操作方式,ORBIT 与 FPS,在 CameraMovement 类中:
ORBIT:以目标为中心,根据鼠标操作进行旋转,旋转限制 lock-y,即左右旋转时永远绕世界坐标系 y 轴,旋转过程如下,
1
2
3
4
5
6
7
8
9
10float dist = GetDistToTarget(); // 相机离目标距离
// 将相机放置目标位置
mCamera->GetParentNode()->SetRelativePosition(mTargetCenter + mOffset);
// 相对于世界坐标系 y 轴旋转
mCamera->GetParentNode()->Yaw(mouseMotion.x * rotSpeed.x, TransformSpace::TRANS_WORLD); // y
// 相对于局部坐标系 x 轴旋转
mCamera->GetParentNode()->Pitch(mouseMotion.y * rotSpeed.y, TransformSpace::TRANS_LOCAL);// x
// 平移保持与目标的距离
mCamera->GetParentNode()->Translate(Vector3f(0.0f, 0.0f, 1.0f) * dist,
TransformSpace::TRANS_LOCAL);FPS:第一人称视角的运动方式,旋转限制 lock-y
3. 场景加载
场景加载由 AssetLoader 的子类完成,基于第三方库 gltf_loader 或 assimp 实现加载接口。场景节点按照层级结构进行创建,并加载其变换信息。节点下的 mesh 数据根据材质种类创建为不同的 PrimitiveEntity,材质的加载包括材质参数的加载以及贴图资源的加载,压缩贴图 DDS 使用 gli 库,其他贴图使用 FreeImage。
由于还没做好场景 UI 界面,因此临时实现将场景层级信息输出到文件进行查看。打开宏 IS_LOG_HIERARCHY_SCENE,场景的层级节点信息会 log 到文件 “intermediate/hierarchy_log.txt”,部分层级如下所示:
1 | |
Mesh 数据的组织方式:目前只有静态 mesh,即不会发生变形的 mesh。在加载资源过程中,按照如下方式组织 mesh 数据:
- 将所有 mesh 数据加载到连续区域的 buffer 中。目前所有 mesh 共享同一连续区域,之后如果支持动态 mesh 后,可能会根据 mesh 类型划分。
- mesh 的数据结构:不直接包含 mesh 原数据,而是保存其 mesh 数据在 buffer 区域中的位置描述,由
PrimitiveEntity持有,- buffer location: mesh 数据所在 buffer 的起始地址
- offset: mesh 数据在 buffer 中相对于其实地址的偏移量
- size: mesh 数据的大小
Draw Call 组织策略
对于一个复杂场景而言,具有很多种类的材质、mesh,往往需要很大量的 draw call 进行绘制,但 draw call 的固有开销又限制了实时条件下硬件能支持的最大数量。在 Nvidia 有关 Draw Call 优化 [1] 的演讲中有提到,draw call 会有固有的驱动层的参数验证开销,这在当时是最大的瓶颈,而这种验证开销是由管线状态改变导致的,下面是不同管线状态改变相对开销对比:
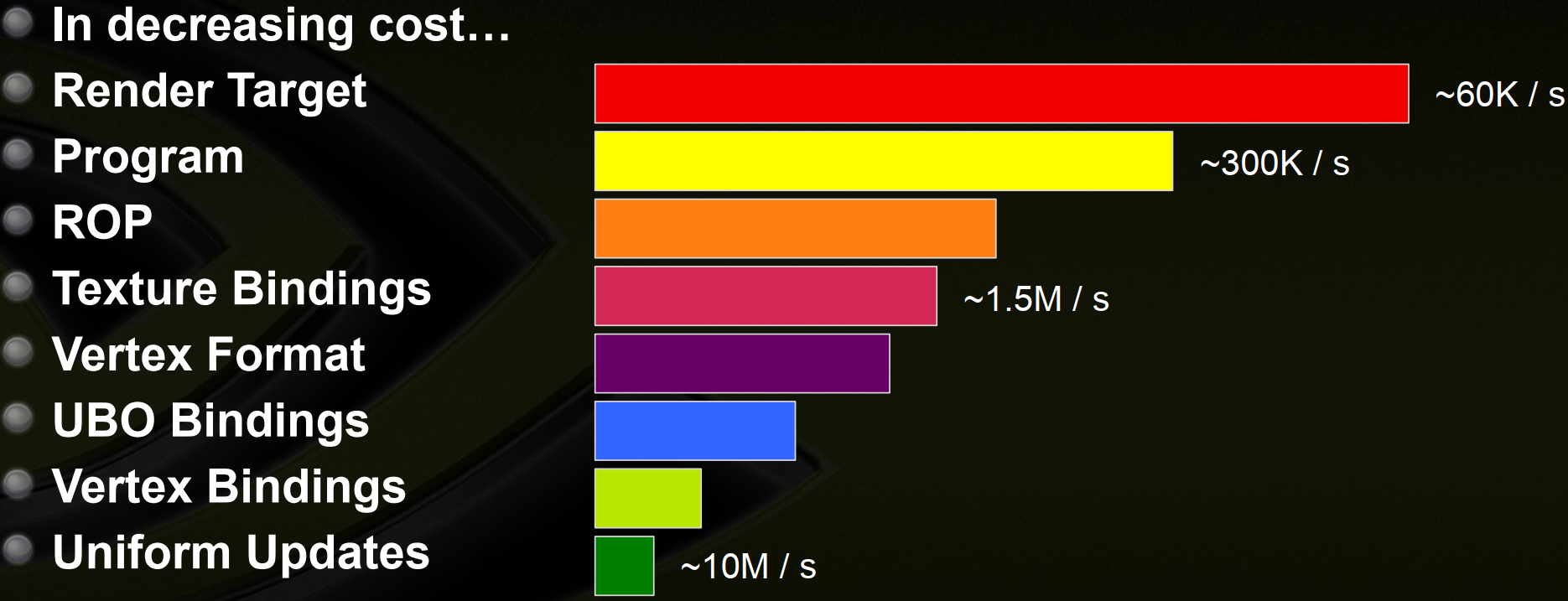
可以看出 render target、shader、texture 的开销依次降低,想要支持的 draw call 数量更大,就要减少这些状态改变。其中提高一些策略:
- 使用 texture array 可以一次性配置好所有 texture,减少 texture binding 的改变
- 使用 SSBO 存储整个场景的 uniform 数据,减少 UBO binding 的改变
- 使用 indirect draw,可以一次性下发一批 draw call,让验证一次完成,减少 draw call 的验证开销
下面介绍上述 draw call 策略的实现
1. 绘制时由 mesh 数据结构到 render proxy
绘制不直接接触 mesh 数据结构,而是使用为每个 render object 构建的 render proxy。在初始化场景渲染信息时,遍历场景结点的 render object 创建 render proxy,并加入场景的 render proxy list 中。一个 render object 可能是一个完整的物体,例如车,而车可能包含多个使用不同材质的 mesh。render proxy 对其拥有的所有 mesh 进行组织,根据材质不同,划分出 meshBatch。每个 meshBatch 保持的是 render object 的一种材质的所有 mesh 信息。因此一个 render object 的 render proxy 包含:
- <mat0, meshBatch0>,<mat1, meshBatch1>,… …
- 其所属场景节点的
node ID proxyIndex:render proxy 在场景的 render proxy list 的索引位置
来自相同的场景结点的 render proxy 可以使用同一个 UBO 传递变换矩阵。不同场景结点的 render proxy具有不同的变换,需要使用不同的 UBO。而不同材质又需要不同的材质 UBO、不同的 texture 等等。如果按照最直接的 indexed draw call,不同材质、不同场景结点的 render proxy 必须使用不同的 draw call,这会使得 draw call 数量非常多。
2. 将大量 render proxy 组织到少量 render group 中
本渲染器使用 MeshMaterialRenderGroup 实现组织 draw call 策略,根据开启的策略,将 render proxy 组织成 render group,一个 render group 即表示了一个 index draw call。下面介绍使用 SSBO、texture array 来从所有的 render proxy 构建出场景的 render group 列表。
2.1 组织策略
Scene SSBO:对于场景节点变换矩阵等节点数据,使用 SSBO 存储场景结点变换数据,存储位置为节点的 node ID。
Group Mat SSBO:对于不同材质的参数、贴图,如果材质可以合并(参数种类相同,贴图格式、大小相同),则合并到同一个 render group。使用 SSBO 存储材质的参数,合并多个材质的贴图为 texture array。材质参数在 SSBO 中的位置为material index。每种材质贴图在 texture array 中的位置也需要一个索引。
Group Instance SSBO:由于一个场景节点可能会有多个 render proxy,因此还需要使用一个 SSBO 来存储 render proxy 所使用的 node ID 与 material index,分别索引 Scene SSBO与Group Mat SSBO,获取 render proxy 的变换、材质数据。
最后配置 render group 的 draw call 使得内置变量 gl_InstanceIndex 能够索引 Group Instance SSBO,也就是 render proxy 在场景的 render proxy 列表中的索引。
2.2 实现 render group 的组织
经过场景中的所有 render proxy 得到很多材质和 meshBatch 的组合,例如 <mat0, meshBatch0>,<mat0, meshBatch1> ,<mat1, meshBatch0>,<mat1, meshBatch2> 等等。依次尝试将每个组合合并到现有 render group 中,如果没有找到可以合并的 render group,则为该组合创建一个新的 render group。对于输入 mat+meshBatch 组合遍历现存的每个 render group,如果同时满足以下条件则可以合并:
- 输入 mat+meshBatch 组合的材质种类是否与当前 render group 的材质种类相同,不相同则不可合并。
- 输入 mat+meshBatch 组合的材质贴图格式、大小等是否与当前 render group 的材质相同,不相同则不可合并。
当一个输入 mat+meshBatch 组合可以合并到目标 render group 时,进行合并操作,为目标 render group 生成一个 group instance:
材质信息存入目标 render group 的材质列表中。该材质位于 render group 中的位置作为索引 material index。由于多个材质可能引用同一贴图,贴图在 texture array 中的索引与材质索引可能不同,因此还需要存储不同贴图的索引,如 baseColor 贴图索引、normal map 索引。以及存储材质参数,如 base color 因子等。这些材质数据都存储在 Group Mat SSBO 的一个元素中,如下例结构体:
1
2
3
4
5
6
7
8
9
10
11
12struct MaterialUniformBufferParams
{
Vector4f BaseColorFactor;
float RoughnessFactor;
float MetallicFactor;
float OcculusionStrength;
uint32_t BaseColorTexIndex;
uint32_t OccuRoughMetalTexIndex;
uint32_t NormalMapIndex;
uint32_t EmissiveMapIndex;
};meshBatch 信息存入目标 render group。如果已有相同的 meshBatch 则为对应 group instance 增加一个 instance 数据,即输入的 meshBatch 对应的
{node index、material index}。如果不存在相同的 meshBatch,则为输入的 meshBatch 新增一个 group instance。这些信息都存储于 Group Instance SSBO 的一个元素中,如下例结构体:1
2
3
4
5struct MeshInstanceData
{
uint32_t NodeIndexInScene;
uint32_t MatIndex;
};render group 的 group instance 创建完成,组织 draw call 信息,得到有效的
gl_InstanceIndex,用以索引 Group Instance SSBO。初始化 instanceOffset 为 0,按照 meshBatch 在 render group 中的顺序,依次进行:- 当前 meshBatch 的 group instance 的数量作为 instanceCount,当前的 instanceOffset 作为 firstInstance
- instanceOffset = instanceOffset+instanceCount
经过以上步骤,可以通过 gl_InstanceIndex 索引 Group Instance SSBO,得到当前绘制 mesh 对应的 node index 和 material index。node index 用来索引 Scene SSBO 获取当前 mesh 对应的场景 node 数据,如 model to world 变换。material index 用来索引 Group Mat SSBO 得到当前 mesh 对应的材质参数,以及材质贴图在 texture array 中的索引。
3. 不同条件下的性能比较
本渲染器目前的场景比较简单:只有静态 mesh,无实时交互,只有单线程,并且场景全部加载。因此直接使用 FPS 进行性能比较。三个相关宏:
IS_SHARE_VTX_IDX_BUFFER:是否整个场景公用同一个 index/vertex bufferIS_USING_MERGE_MATERIAL:是否合并材质,使用 texture arrayIS_USING_INDIRECT_DRAW:是否开启 indirect draw,
测试场景一共创建了 170 个 mesh render proxies。
- 关闭所有选项使用最直接的 index draw call:组织为 170 个 render group,每个 render group 需要一次 index draw call,FPS 为 65 左右
- 只开启
IS_SHARE_VTX_IDX_BUFFER使得 170 次 index draw call 都使用同一个 index/vertex buffer,FPS 无明显变化 - 只开启
IS_USING_MERGE_MATERIAL,将材质可以合并的 mesh 合并为一个 render group,一共得到 6 个 render group。每个 render group 使用一次 index draw call,同时使用一个 index/vertex buffer,FPS 提高到 142 左右- 同时开启
IS_USING_MERGE_MATERIAL和IS_SHARE_VTX_IDX_BUFFER,即 6 次 index draw call 共享同一个 index/vertex buffer。FPS 无明显改变。
- 同时开启
- 只开启
IS_USING_INDIRECT_DRAW,这时 IS_SHARE_VTX_IDX_BUFFER 也会同时开启。将所有 index draw call 参数存到一个 indirect buffer 中,使用一次 indirect draw 将所有 index draw call 提交。因为没有合并材质,因此共生成 170 个 render group,即 170 个 index draw call,每个 render group 在一个 indirect draw 中提交。FPS 为 68 左右,比最直接的 index draw call 有些许提高。本测试场景瓶颈在材质种类数量,而不在节点数量,因此不合并材质 indirect draw 发挥不了作用 - 同时开启
IS_USING_INDIRECT_DRAW和IS_USING_MERGE_MATERIAL,一共生成 6 个 render group,即 6 个 index draw call,在一次 indirect draw 中提交。FPS 为 650 左右,相比于最直接的 index draw call,提升了 10 倍。就算对于仅合并材质的情况,即使用 6 次 index draw call,也有将近 4.5 倍提升。
Reference
[1] https://developer.nvidia.com/content/how-modern-opengl-can-radically-reduce-driver-overhead-0