DACHash A Dynamic, Cache-Aware and Concurrent Hash Table on GPUs
1 Summary
对于GPU的高并发以及SIMT(Single Instruction Multiple Threads)执行模型而言,cache命中率对性能的影响很大。作者提出reorder算法提高对hash table数据访问的局部性,这也是该方向的首次研究与尝试。
2 Basic Design and Implementation
本章节介绍了DACHash的基础设计与实现,包括数据结构、hash table的操作与内存管理。
2.1 Base Data Structure and Organization
hash table的bucket是一个以小型数组为结点(super node)的链表,其中数组的每个元素是key-value对,如下图所示。连接bucket头的super node是预先分配好的,后续super node则是实时动态分配与释放的。
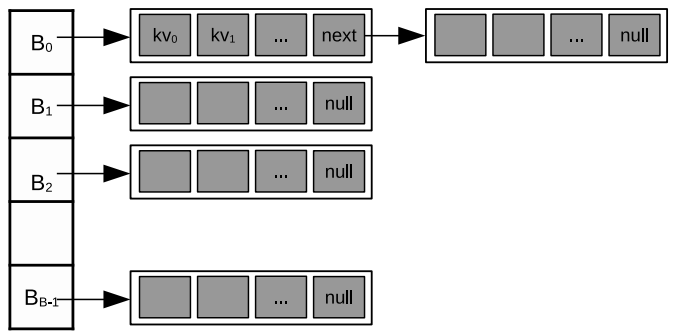
这种数组的链表结构对于哈希表而言更像是一种对开放地址与拉链法的折衷,既能方便解决冲突,又能支持GPU-friendly的并行(数组具有高cache命中率)。
2.2 Operations
作者通过cuda的atomic functions实现了hash table的常见操作
2.2.1 Search
search操作用于在hash table中查找给定key,并返回对应的value。如果没有找到key,则返回null。执行过程:
- key经过hash定位到bucket
- 从bucket第一个super node逐条查找,直到
- 找到对应key,返回value
- 查找到bucket链表末尾,返回null
2.2.2 Insert
insert操作添加一个key-value对到hash table中。执行过程:
- 如果key已经存在于hash table中,那么insert表现为与update相同的操作。
- 如果key不存在,查找一个empty slot,并插入新的key-value对,这可能会带来super node的动态申请
- 在bucket的链表中查找一个empty slot,使用 atomicCAS。
- 如果查找到链表最后,没有找到empty slot,申请一个新的super node。使用 atomicCAS 链接到bucket链表末尾。
- 可能同时有多个线程尝试链接自己申请的super node到bucket末尾,但只会有一个成功
- 失败的线程释放掉申请的super node,在bucket新的尾结点重新尝试插入操作
2.2.3 Update
update操作查找一个key并更新对应值。如果key能找到,那么使用 atmoicExch 更新value。如果key找不到,那么执行insert操作。
2.2.4 Delete
delete操作将指定key标记为deleted,与search操作类似,只是没有返回值。执行过程:
- 从bucket第一个super node开始遍历,直至
- 找到对应key,标记为deleted
- 遍历到bucket链表末尾
2.2.5 Clean
clean操作紧凑bucket的super node链表,确保只有最后一个super node有empty slot。clean操作在单独的kernel执行(对应compute pass),所以不会有其它操作的妨碍。clean操作只会在memory stack空的时候执行,会将空super node释放,放回memory stack。
2.3 Memory Stack
insert、update、delete、clean操作可能需要super node的动态申请与释放。为此,预分配大量super nodes,并放入concurrent stack,如下图所示
- pop:申请一个super node
- push:释放一个super node
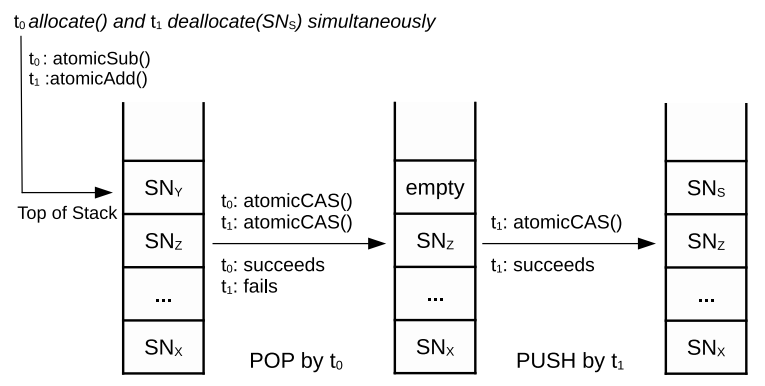
这里作者没有给出实际的算法。自己调研了下GPU上并行栈的算法,基本核心都是解决 ABA problem[3] ,但本文中的memory stack中没有重复元素,因此可以简单实现。
contention处理:当多个线程同时竞争同一top指针时,每个线程迭代执行直到操作完成,可以看作一次迭代只会有一个线程完成操作。这里以glsl的原子操作介绍实现:
使用
atomicAdd得到target_top,即当前线程操作的目标位置。多线程同时竞争到同一top指针时,只有当目标位置满足操作要求时,才会完成操作。例如push操作需要目标位置为空,pop操作需要目标位置不为空
使用
atomicCompSwap来循环判断目标位置是否满足条件。
实现如下
1 | |
3 Reorder
如果一个warp的输入keys被哈希到不同的bucket中,由于bucket之间或之内的super node在内存中是分散的,因此这个warp的线程发出的内存请求很可能位于不同的cache line(uncoalesced),而不是同一个cache line(coalesced)。也就是说,这个warp具有较差的局部性。
SlabHash[2] 提出了wrap内的 work-sharing 策略来提高coalesced memory access。该策略大概是一个warp并行处理一个super node,即一次执行单个key,这样warp的线程只需要一次全局内存访问,后续都只在cache中。但对于链表的遍历过程,该策略可能会重复遍历,带来较差的局部性问题。
下图描述了一个cache命中率较低的访问示例。假设一个大小为4的warp要处理keys {0, 3, 7, 8},处理过程如下:
- warp处理key 0,对应bucket 0,并加载了第一个super node。但加载super node同时加载的其它key并未被使用到。处理其它key也会遇到这种情况。
- warp再处理key 3、key 7,遇到了同样的问题。同时,随着bucket 3与bucket 7的super node的加载,key 0的数据很可能从cache中被逐出。
- warp处理key 8,bucket 0的第一个super node再次被加载,降低了cache命中率。
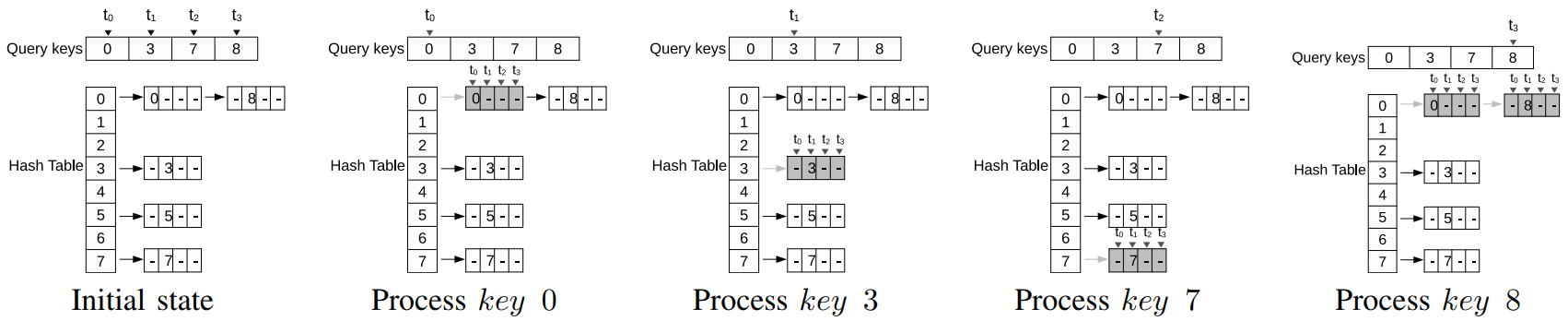
为了提高链表遍历过程中的cache命中率,作者提出对keys的reorder算法,将相同hash value的keys组织在一起。这一步是将super node的内存区进行划分,通过reorder算法,使得相同hash value的key的super node在物理上也相邻。
Algorithm1描述了reorder算法的伪代码过程,关键变量有:
- 二维数组 buffer
ReorderSpace[B][M],其中 B 为bucket数量,M = ceil(N/B),N为 keysList 的大小。- 行索引定位为 bucket value
- 列索引为bucket内存区域的index
- 值为key
Record[B]用来追踪每个bucket的最新index
关键处理有:
line 8:分配一个bucket内存区域的index。相同bucket的key是会被映射到
ReorderSpace的同一行line 9-11:
ReorderSpace的M其实是认为keys能够在bucket间均匀分布,但这一点很可能不满足。当不均匀发生时,就会出现 index >= M 的情况。在 index 超出范围时,尝试使用下一个bucket的index,直至满足条件。
line 12:最终将key加到
ReorderSpace中

只有在reorder完成后,后续的操作才能被执行,因此这里需要加上同步操作。同时为了加快reorder以及节省内存,也可以选择将相近的hash value组织在一起,例如 line 3 将 B 改为 (B/4)。
这个岂不是需要提前得到要处理的 keys,大概是接收到keys后需要先进行reorder,再执行后续的操作。
4 Dynamic Mapping Schemes
在以thread group处理一批keys时,有两种 thread-data mapping模式:
one-to-one mapping scheme:每个线程负责一个key,因此warp的32个线程可以独立地处理32个keys中的一个。
由于32个key很可能hash到不同的bucket,因此这种模式的内存访问是比较分散的。
由于查找过程是独立的,因此这部分操作很可能有差异,导致一个warp的线程退出时间不同。
many-to-one mapping scheme:一个warp的线程共同协作处理32个key,一次处理一个key。
key的查找过程使用warp的线程并行处理一个super node,访存更连续。
由于并行处理一个key,过程基本都是一样的,一个warp的线程会汇聚到一个时间点。之后再处理不同的操作。
作者提出按照如下方式动态选择mapping模式
$$
D = \left{
\begin{array} {rcl}
O \quad \quad if \quad \epsilon < \tau \
M \quad \quad otherwise
\end{array}
\right.
$$
其中,$O$ 是 one-to-one,$M$ 是 many-to-one;$\epsilon$ 是 expected length,即bucket包含的super node数量的平均值;$\tau$ 是调控的阈值。
下面是两种mapping模式的算法伪代码。可以看出,one-to-one模式下,每个线程都独立处理一个key,每个key的查找过程可能不同、操作可能不同,因此它们的完成时间也可能不同,导致较低的执行效率。many-to-one模式下,将线程划分成 CG_SIZE 大小的tile,一个tile协同处理一个key,tile内可以使用cuda shfl() 与 ballot()原子操作来通信,tile执行的底层指令更可能相同。


Reference
[1] Zhou, H., Troendle, D., Jang, B., 2021. DACHash: A Dynamic, Cache-Aware and Concurrent Hash Table on GPUs, in: 2021 IEEE 33rd International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD). pp. 1–10. https://doi.org/10.1109/SBAC-PAD53543.2021.00012
[2] S. Ashkiani, M. Farach-Colton, and J. D. Owens, “A dynamic hash table for the gpu,” in 2018 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2018, pp. 419–429