Coherent Memory Access and Synchronization
1 Summary
经常看到glsl的type修饰 coherent,系统整理下有关coherent的理解。
2 基础概念
2.1 Coherent or Incoherent Memory Access [2]
2.1.1 Coherent 内存访问
以最简单的例子——单处理器系统来说,对于同一内存区域同时只会有一个线程访问。因此,当一个处理元件对某一内存区域写,然后另一处理元件对同一内存区域读时,总能读到更新后的值。这是我们想要的结果,但得到这一正确结果并不只是多线程读写同步。因为,在硬件层有高速缓存-内存机制,处理器的读写往往不直接针对内存,而是针对缓存。缓存中的数据是内存中数据的拷贝或者是写操作得到的更新数据,因此需要确保写操作之后的读操作能够读到新数据,而非旧数据,这就是 Coherent 内存访问。单处理器系统的内存操作工作于同一套高速缓存-内存机制中,保证 Coherent 内存访问较容易。
2.1.2 Incoherent 内存访问
但对于多处理器系统,每个处理器都有其本地缓存,当多个处理器同时访问同一内存区域时,同一内存区域的数据在这些处理器的缓存中都有一个备份。此时可能存在处理器读到的是本地缓存中的旧数据,而不是其他处理器写操作生成的新数据,即出现 Incoherent 内存访问。为了避免这种情况,多处理器系统的设计需要采用存储器一致性协议,粗略地说,当一个处理器对某一内存区域更新时,对该内存区域存在缓存备份的其他处理器也要对其本地缓存的相应位置进行更新。
2.2 GPU Architecture
GPU 具有非常多的处理器核心,在 Nvidia 中称为 Streaming Multiprocessor(SM),AMD 称为 Compute Unit(CU),以下使用 SM。在 SM 内部包含最基本的处理单元 lane,lane 可以近似理解为一个线程。SM 进行调度执行任务时,最小单位并不是 lane,而是 Warp(Nvidia 中的称呼,AMD 称为 wavefront)。一个 Warp 包含一定数量的 lane,在 Nvidia 中是 32,AMD 是 64。不同的架构,一个 SM 中包含的 warp 数量不同,目前的 Nvidia GPU 中一个 SM 包含 4 个 warp,即 128 个 lane(shader core、cuda core等)。GPU 显卡型号不同,GPU 包含的 SM 数量也不同,3080Ti 包含 80 个 SM。
下面来自 [4] 的图 Fig-1 为GPU示意图,Fig-2为其中单个SM示意图。
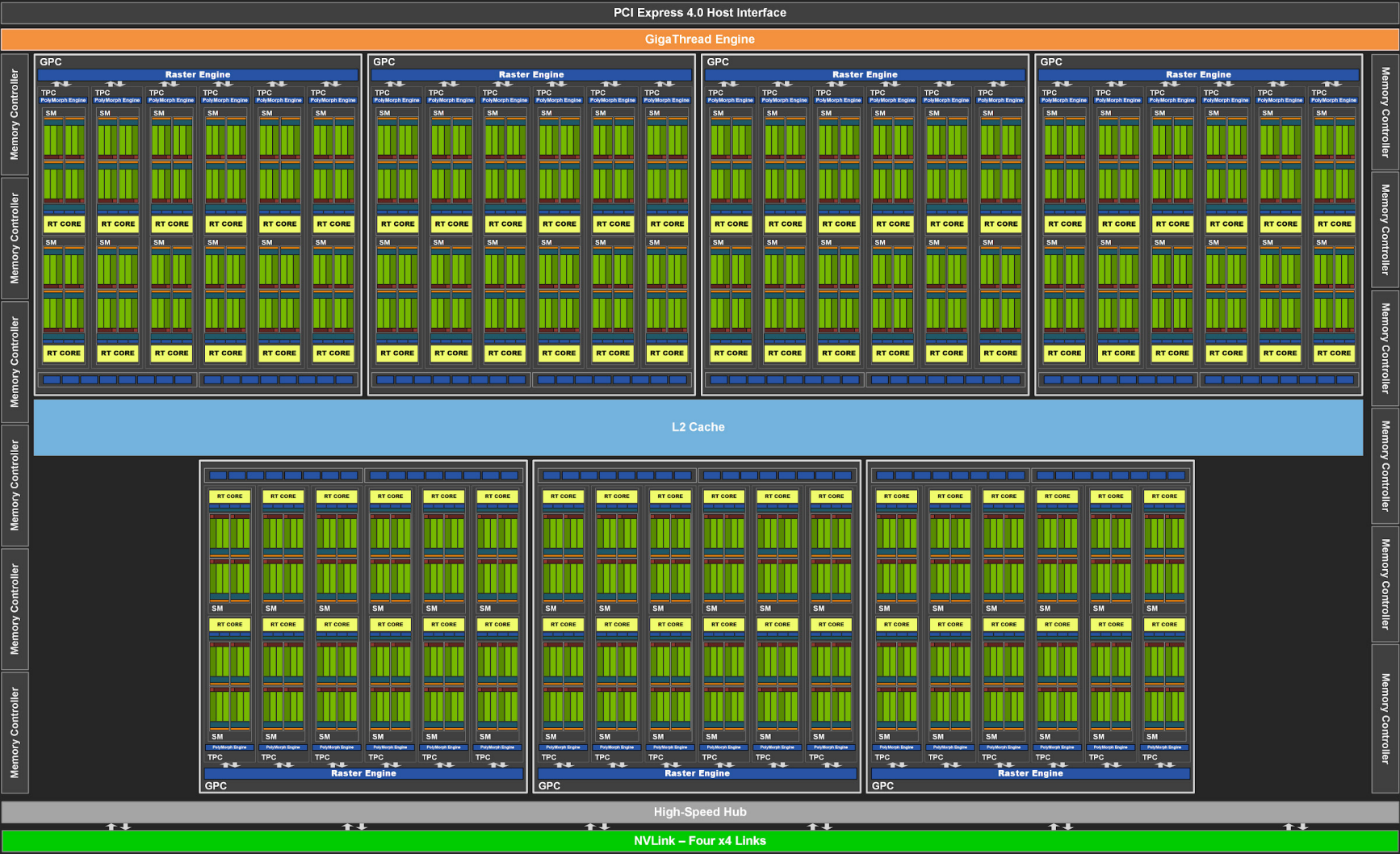
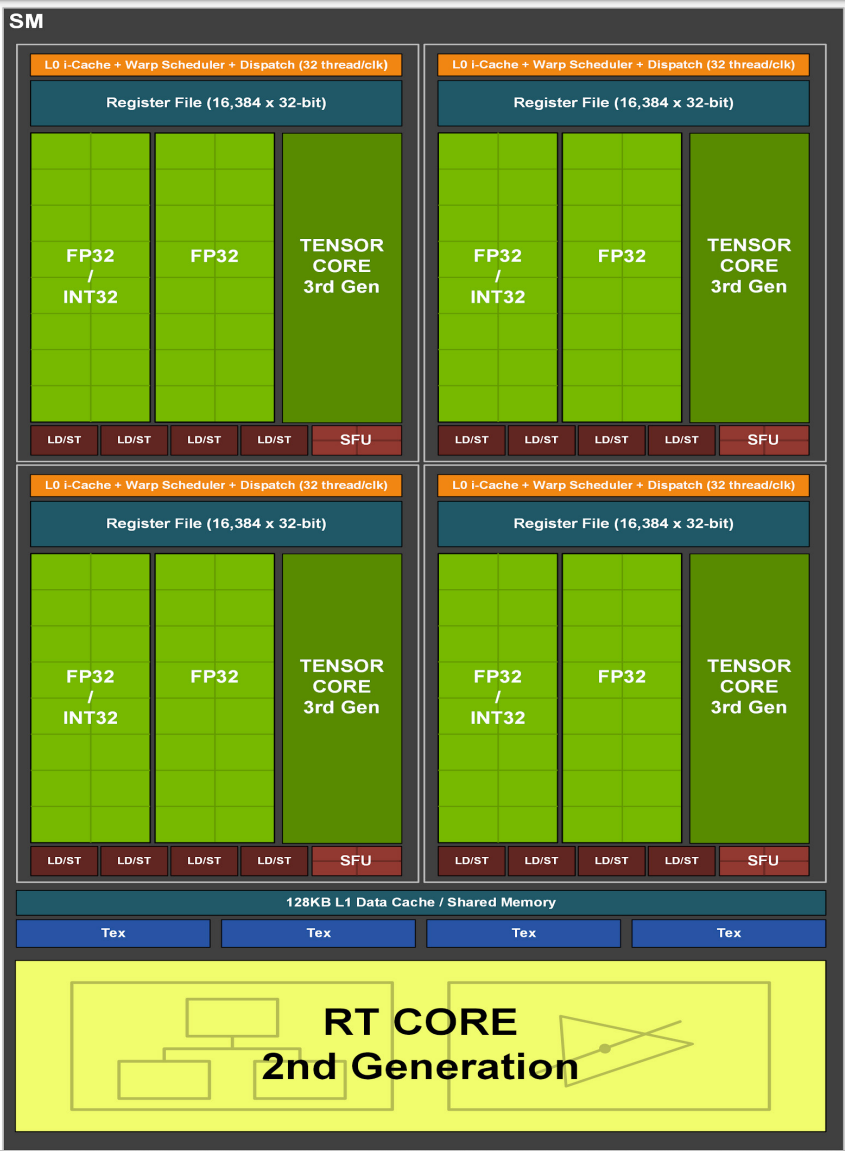
2.2.1 Memory Model
从Fig-1中可以看出,整个GPU共用一个L2 cache,而Fig-2中每个SM都有一个L1 cache。下面Fig-3 是来自 [3] 的GPU内存的简化模型,即 L1 cache - L2 cache - DRAM 这样的三层结构,
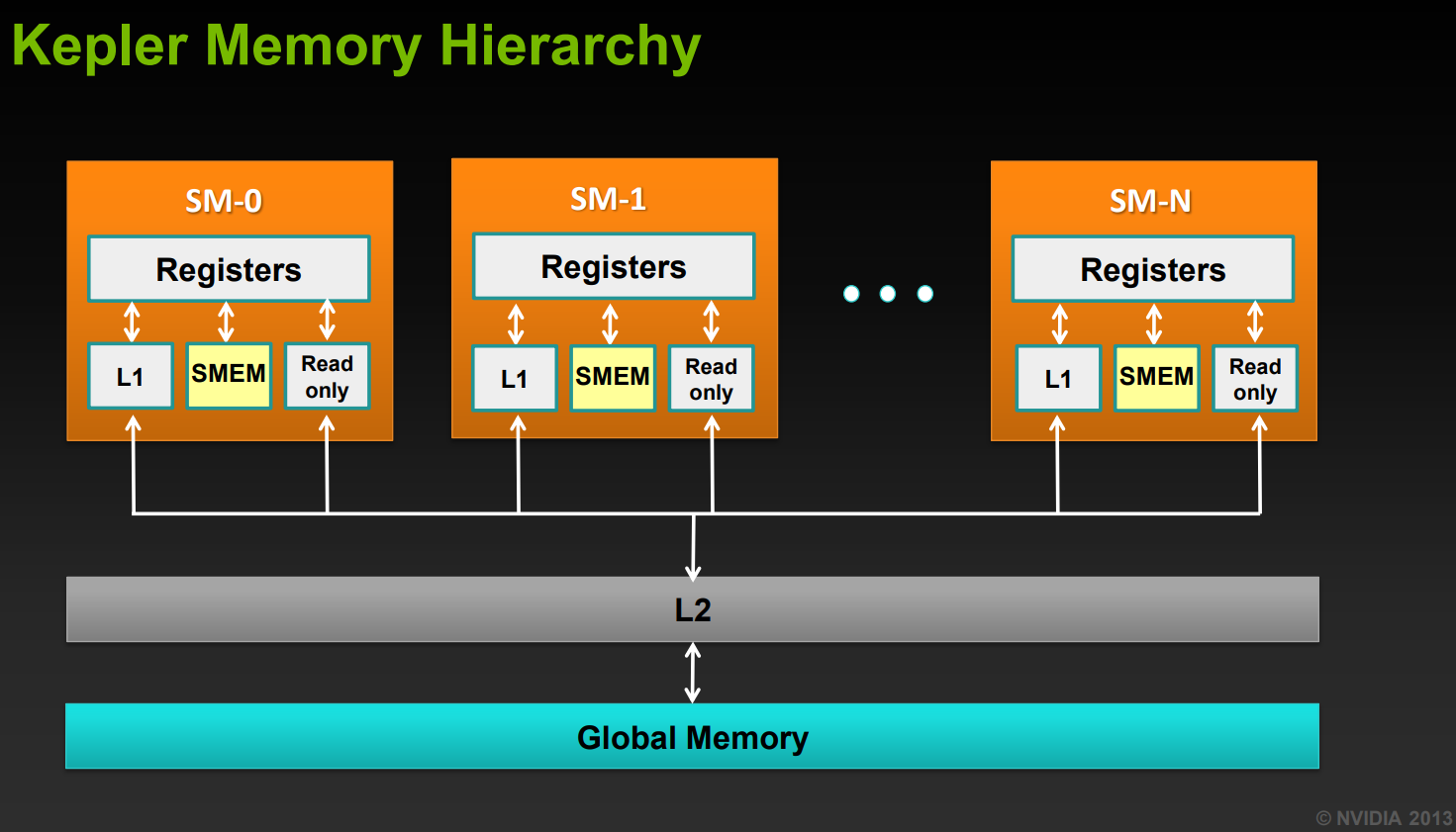
其中:
register:每个 SM 具有256KB 大小的寄存器区。
shared memory/L1 cache:一个 SM 中的所有线程可以访问该 SM 具有有限大小的 shared memory。shared memory 本质上是一个较小的读写缓存区,GA102 架构中为 128KB,但其中只有一部分可被程序员使用,其他用作缓存或其他用途,例如 48KB 用作 shared memory。
L2 cache:通过L2 cache访问DRAM
global memory(DRAM):global memory 即 GPU 显存。如果寄存器存储或者shared memory 的使用大小溢出,则会将其中的数据写入显存中,这一点和 CPU 的高速缓存-内存机制类似。
按照2.1节的概念,正是这样的两层cache的结构引入了内存访问的coherent问题。


2.2.2 Execution Model
对于GPGPU,用户调度方式是通过cuda或者compute shader发出多个thread group。而GPU收到这些thread group如何调度执行就是execution model。
在同一个 Warp 中的所有 lane 执行相同的指令,但可以处理不同的数据,这样就构成了现代 GPU 的 SIMD 机制。但一个 Warp 中的所有 lane 并不总是同时处于运行状态,即 active lane;也并不总是同时处于非运行状态,即 inactive lane。例如:
下发的任务组包含的任务数量较少或者不是 warp 大小的整数倍,不足以填满整个 warp 的 lane,那么未分配任务的 lane 则处于 inactive 状态。下发的任务组在 vulkan 中称为 local workgroup(D3D 中的 thread group) 大小。
Dynamic Branching 会导致 lane 的执行路径不止一条,即不止一套指令,这一定程度上破坏了 SIMD 机制。例如,代码中包含 if-else 语句,不满足 if 条件的 lane 由于 lockstep 运行方式需要等待其它所有满足 if 条件的 lane 执行 if 部分,等待中的 lane 则处于 inactive 状态。反之,满足 if 条件的 lane 也会等待不满足 if 条件的 lane 执行 else 部分。
接下来,基于 [3] 关于cuda执行模型的资料(理论上都是一样的)来介绍。cuda中的执行单位有:
thread:对应compute shader中的invocation
threads block:对应work group
运行在一个SM上,因此 threads block 内的线程可以有轻量级地同步与数据交换。
- 同一个SM共享一个L1 cache,因此可以仅使用shared memory,要快于buffer、image这类global memory。
- 同一个warp线程也可以使用warp内的数据同步(更快)
当一个threads block被调度到某一个SM上时,就只会在这个SM上执行 (中间可能会有hide latency导致的换入换出),否则L2 cache就无法保证是同一个。
grid:grid大小 (x, y, z) 对应dispatch中的参数,一个grid包含 x*y*z 个threads blocks。
这些blocks如何被调度由GPU决定,是不可知的,也就是无法知道哪些blocks会在一个SM上执行、哪些在不同SM上执行。因此需要统一视为在不同SM上。
不同threads block之间无法同步,数据交换只能通过global memory
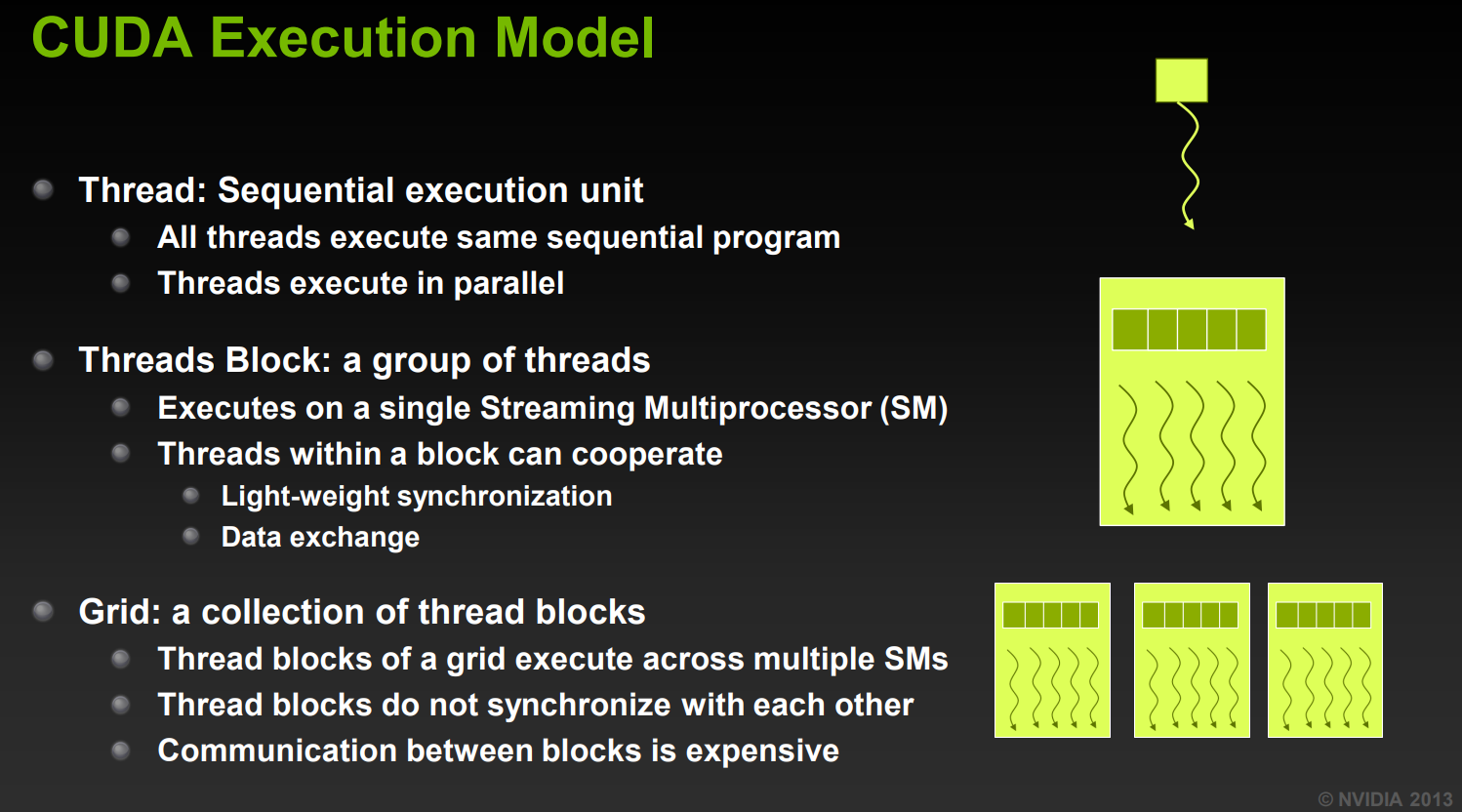
2.3 Synchronization
同步主要包含两类:
- 对代码指令执行结点的同步。全部执行到同步点时才会开始执行之后的指令,这类同步只能发生在thread block(work group)内。
- 对内存访问操作的同步。保证能够读到已经执行的写操作后的数据,避免读到cache中旧的备份。这里的访问操作不是显示调用的指令,而是cache机制中隐含的memory transaction。
下面基于glsl对这两类同步进行阐述。为了解释内存操作的同步,先看下OpenGL对visibility的描述。
2.3.1 Visibility [5]
在 GPU 的执行过程中,不同处理器同时读写同一内存区域时,也会出现上述 Incoherent 内存访问情况。而 Visibility 术语就是指一个 shader invocation 可以安全地读其他 shader invocation 的 Incoherent 写数据,也就是说,不会读取到缓存中旧的备份,或者其他 invocation 写数据对其是可见的。
避免 incoherent 内存访问,即确保 visibility 性质。这里有两种情况:
2.3.1.1 Internal Visibility
发生在一个 render command 执行内部,即shader invocations之间。[6] 中提到shader中的 incoherent访问操作有:
对 image 变量的 imageLoad/imageStore
对 buffer 变量的读写操作
对 compute shader 中的 shared 变量的读写操作。:x:
这一点应该是错的。shared 变量位于shared memory即L1缓存中。根据2.2.1小节内容,L1 cache位于SM内,是独立的且对其它SM不可见,因此不会有多个备份的情况,所以不会是 incoherent。
后面也有官方资料证实shared变量是隐含的coherent。
2.3.1.2 External Visibility
一个 render command 内部的 visibility 是 shader invocation 之间的读写操作。对于 render command 之间的 visibility 使用 barrier 命令进行同步。例如 vulkan 中的 buffer barrier、image layout 等。
2.3.2 指令同步
由2.2.2小节中描述的cuda执行模型可知,不同work group之间无法同步,因此这里的同步是work group内的。
glsl 中函数 barrier()可以确保workgroup(执行在同一处理器) 中的所有 invocation 都执行到 barrier 同步点后,才开始执行之后的代码。其在官方文档 [7] 8.16节中的描述如下

在 compute shader 中 shared 变量位于 shared memory 中,即位于L1 cache中,同一SM只有一份,因此 shared 变量是隐含的 coherent 访问。barrier同步的是同一workgroup的指令,因此也能做到对shared变量的访问同步。这一点在 [7] 的 1.1.3 小节也有说明

思考另一点,同一work group的invocation都位于同一SM,那么为什么还需要barrier来同步指令?位于之前的指令不应该先于之后的指令完成吗?
那是因为,GPU调度单位是warp,对于一个提交的work group,work group被分配好SM后,会先被划分为一个或多个warp,以warp为单位调度执行。一个SM共有4个warp,如果不足以执行完整个work group,那么会需要多次调度执行。因此work group虽然都在同一个SM上,但其中的warp可能不是同时开始或结束的。对于 barrier 同步而言,执行到同步点的warp会停下来,此时SM可以再调度一个warp进来执行。
2.3.3 Memory Barrier
指令同步无法解决前面说的incoherent内存访问问题,首先是指令同步只能发生在work group内,其次不同work groups可能分布在不同的SM上,仍然会导致incoherent问题。
复述incoherent问题:写操作发生不代表写数据对其他 invocation 可见,这会导致一个 invocation 的内存读写操作的相对次序对于另一个 invocation 而言是不确定的状态,换句话说,写操作的数据对其他 invocation 可见的次序不确定。例如一个 invocation 中执行两次写操作,而另一个 invocation 可能会先看到第二次写的数据,后看到第一次写的数据。
memory barrier 则是用来控制读写操作(背后的cache机制),使得其他 invocation 看到写数据的次序与写操作执行的次序一致。先对可能被多个处理器访问到的 image 或 buffer 类型变量进行 coherent 修饰,声明该变量为 coherent 访问机制。该访问机制使得相应的 memoryBarrier 可以控制对被修饰变量的读写操作。调用 memoryBarrier 等函数的 invocation 会等待之前的所有读写操作完成,当该函数返回后,写数据对之后的访问处于可见状态。
memory barrier有以下几种类型, 来自[7] 的 8.17节 :
memoryBarrier:控制所有类型变量的内存访问,render command 内作用于全局。memoryBarrierAtomicCounter:控制 atomic-counter 变量的访问,render command 内作用于全局。memoryBarrierBuffer:控制 buffer 变量的内存访问,render command 内作用于全局。memoryBarrierImage:控制 image 变量的内存访问,render command 内作用于全局。memoryBarrierShared:控制 shared 变量的内存访问,作用于同一 workgroup。groupMemoryBarrier:控制所有类型变量的内存访问,作用于同一 workgroup。

官方文档 [7] 后续有些描述可以更清晰理解这些memory barrier的作用
- 作用范围:只有
memoryBarrierShared()与groupMemoryBarrier()只会控制同一work group的memory transaction,其它memory barrier都是作用于render command的所有invocation。
- 对于执行store的invocation而言,不需要memory barrier来保证其自身的观察到store次序。除非有其它invocation对同一内存位置写入。

一些疑问与猜想:
- 对于不同work group不会对同一内存位置读写的情况还需要memory barrier吗?例如多个work group处理一张图片,每个work group负责一个tile。
感觉应该不需要,对不同位置操作,没有带来对同一位置多份cache的情况 groupMemoryBarrier()只对同一work group的memory transaction起作用,这似乎没有意义?因为同一work group在同一SM上,具有相同的cache,memory transaction应该不会导致incoherent问题 :question:- 按照上面第二段的解释而言,如果work group内的每个invocation负责访问不同的内存位置,那么确实不需要该memory barrier。
- 如果work group内的invocation可能访问同一内存位置,按照我的推测,应该是缓存机制没办法保证访存(store/load)的原子性,而work group的invocation属于并行线程,会导致多线程读写问题。
groupMemoryBarrier()可以保证memory同步点之前的memory transaction完成,可以确保写后读的正确性。
2.3.4 Atomic Memory
官方文档 [7] 8.11 节描述了对 buffer/shared 变量存储的atomic操作,
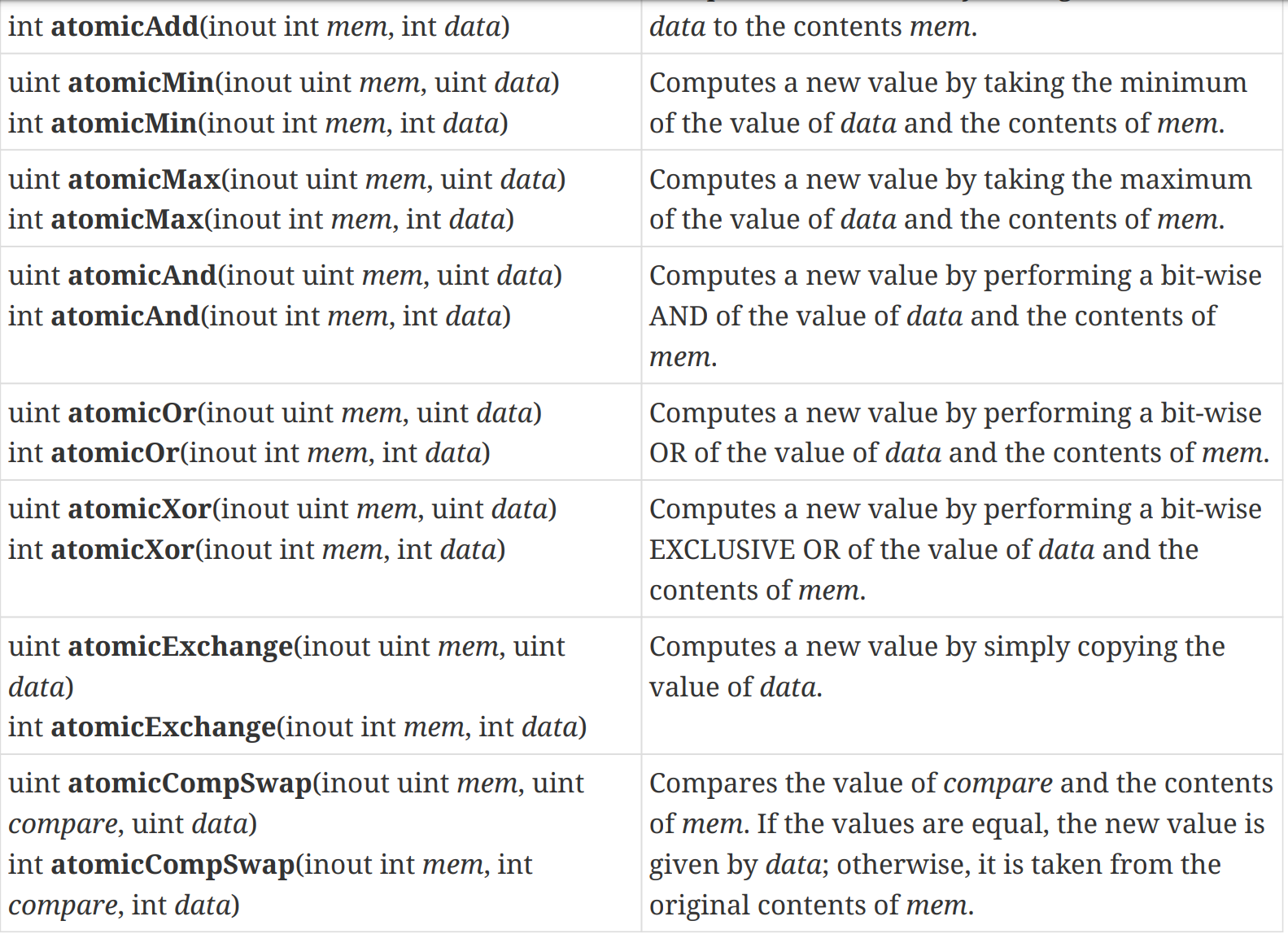
而atomic操作可以满足memory qualification,如下所述。理论上应该是可以保证coherent访问的,那读取操作应该需要使用 atomicAnd(mem, 0xFFFFFFFF)

Reference
[1] https://docs.nvidia.com/deeplearning/performance/dl-performance-gpu-background/index.html#gpu-arch
[2] https://en.wikipedia.org/wiki/Memory_coherence
[3] https://www.olcf.ornl.gov/wp-content/uploads/2013/02/GPU_Opt_Fund-CW1.pdf
[4] https://images.nvidia.cn/aem-dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf
[5] https://www.khronos.org/opengl/wiki/Memory_Model#Ensuring_visibility
[6] https://www.khronos.org/opengl/wiki/Memory_Model#Incoherent_memory_access
[7] https://registry.khronos.org/OpenGL/specs/gl/GLSLangSpec.4.60.pdf