GI-1.0 - A Fast Scalable Two-Level Radiance Caching Scheme for Real-Time Global Illumination
1 Summary
2 GI-1.0
对于实时渲染,尽管是在目前的高端显卡上,也只能支持每像素很少的样本数量。本文提出的全局光照管线,通过设计的两级radiance cache,在空间、时间上复用样本的光照信息,如下图所示:
- screen cache:将primary path上顶点的入射radiance缓存到直接可见表面上的probe中,具有精细的光照表示。
- world cache:缓存了secondary path上顶点的出射radiance,相比于screen cache,不够精细但具有稳定和持久的优点。
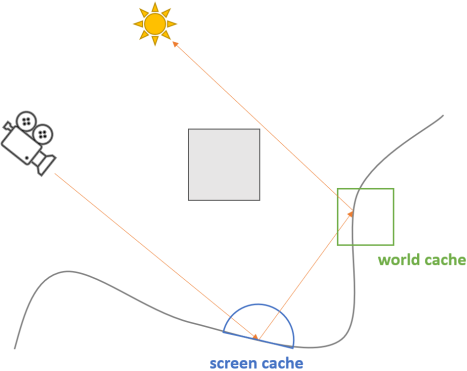
基于这两级radiance cache,本文提出的GI管线可以提以 1/4 spp 的采样率实现高保真的直接与间接光。
2.1 Screen Cache
screen cache 是基于screen probe的实现,本章节会介绍如何将screen probe稀疏地生成在像素上;如何在帧间管理cache数据结构的完整性;以及如何应用 filtering 启发式策略来确保光照在任意距离下的时序稳定性。
与 [2] 一样,在半球面入射的radiance会以八面体映射[3]的方式编码到 8x8 单元的地图集中。
2.1.1 Temporal Upscale
前面提到,screen probe 只能在屏幕像素上稀疏地生成。在本文提出的方法中,screen probe的生成分摊在多帧。先预设屏幕多大tile放置一个probe,每帧生成不同tile的probe,然后通过重投影复用历史帧的probe,最终几帧后达到覆盖屏幕的全部 tile,即 upscale 到全分辨率。upscale 系数决定了采样率,可以作为性能与质量的权衡。本文的实现中选择使用一个 probe 来编码一个大小为 $8\times 8$ 的 tile 的半球radiance信息,同时每个probe分辨率为 $8\times 8$。因此,这里可以将生成screen probe的tile大小定义为 $8\cdot (upscale_x, upscale_y)$ ,其中 $upscale_x$、$upscale_y$ 分别表示 X、Y 上的时序 upscale 量,越大意味着需要更多帧达到全分辨率。
在为每个tile生成一个screen probe时,作者使用 Halton 低差异序列在 tile 内抖动选择一个像素作为生成位置。当 upscale 选择 $(2,2)$ 时,则需要4帧能够达到完全填充,即每个tile至少具有一个probe,如图 Fig-2 所示。
这里的说法有点冲突。Halton序列应该是将spawn tile划分成立 upscale_x * upscale_y 份,每次在其中一份(probe grid/tile)中抖动生成一个probe

temporal upscale 依赖于probe重投影。为了不降低质量,需要确保重投影过程的准确性。在使用 motion vector 重投影上一帧probe时,得到的对应是当前帧的一个 probe tile,因此还需要确定重投影到tile的哪个像素上。作者提出一个启发式策略,用来在probe tile内找到与上一帧probe最匹配的像素。下面是确定最匹配像素的算法伪代码,其中 cell_size 是一个启发式参数,用于控制能够接受多大程度的 spatial error,该参数在后面也会用到。
1 | |
上述算法应该是要先将上一帧probe所属tile投影到当前帧,得到 probe tile,然后再对 probe tile 内的每个像素执行上述打分过程,分数越高表示像素与重投影probe的差异越大,因此需要取其中的最小值。此外,算法使用一个 32bit 的高16位存储socre、低16位存储lane编号,这种做法是为了让比较过程由score的关系确定,而lane编号对比较没有影响。最终得到最小score时,同时可以得到lane编号,从而确定对应的pixel。但不知道 pack_half 怎么实现的? :confused:
2.1.2 Adaptive Sampling
前一小节描述了重投影复用上一帧的probe,可以很快达到覆盖全分辨率,但实际中往往会发生去遮挡 (disocclusion) 情况,此时去遮挡区域会找不到重投影probe,如 Fig-3 左图所示

当发生去遮挡时,一种解决办法可以是创建新的probe,来填充这些空白区域,但这会导致spp增大、开销增加。作者提出从时序重投影成功的tiles中随机挑选一部分,分配给这些空白tiles,这样可以保持稳定的开销。为此需要生成两个queues:
- empty_tiles buffer:存储重投影失败且没有新生成probe的tile列表
- override_tiles buffer:存储重投影成功且新生成probe的tile列表
接下来,为每个 empty tile 随机选择一个 override tile,并放入spawn_tiles内,算法如下。
1 | |
该算法通过重分配一定的光线样本预算,来填充时序空洞,效果如 Fig-3 右图所示。
算法使用数组存储索引的方式来重定向tile,在生成光线样本阶段,会从 spawn_tiles 中获取真正的tile。spawn_tiles 应该是总tile数量的大小,存储的是每个tile索引对应要生成probe的tile索引。在没有重分配算法下,spawn_tiles[index] = index。重分配算法中,会将其中一部分override tile修改为empty tile,即 spawn_tiles[override tile] = empty tile。
2.1.3 Ray Guiding
前面小节完成了放置probe,接下来需要为probe生成光线样本,即如何在八面体的cells中分配光线。作者采用与 [2] 相同的方法,根据上一帧结果进行重要性采样。实现上,先将重投影的radiance的luminance写入Local Data Share (LDS),再通过warp/subgroup指令并行扫描,标准化为 Cumulative Distribution Function (CDF),最后使用 CDF 随机选择一个cell。

为了提高guiding过程的准确性,需要半球重建尽可能忠实。这里的重建在 3x3 tiles邻域内迭代重投影probe,并累积radiance值到还未计算的新生成probe中最匹配的cell上。但在不同probe的cell之间重用数据,需要先解决它们之间的视差问题,如 Fig-5。光线样本的 alpha 存储了hit距离,因此可以恢复出重投影cell的 hit position,基于此可以在重投影的radiance散布到新生成probe之前,执行视差矫正。
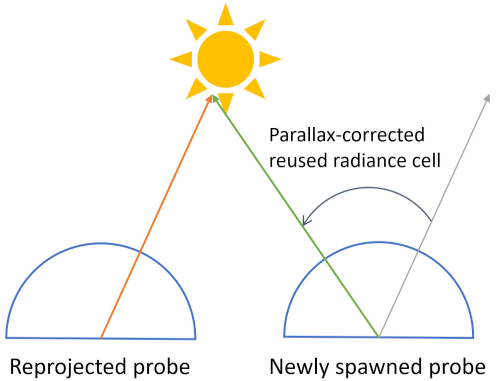
radiance的scatering过程通过在LDS中分配 8x8 八面体图来高效实现重建与采样。与 2.1.1 小节类似,使用 cell_size 拒绝掉较远的probe。
到此,probe的光线样本都已生成,接下来执行光追与场景求交。当无交点时,认为交到天空,将环境光加入光线;当有交点时,则需要计算交点处的光照,这是通过后面的hash cells data structure来实现的。
2.1.4 Radiance Blending
此时,我们得到了所有光线样本的radiance信息,但由于ray guiding,八面体的同一cell可能会由多个光线样本,这些样本直接使用重要性采样加权平均即可得到当前新的radiance。除此之外,还需要将新的radiance与上一小节重建的radiance进行时序混合。对于blend方式的选择,exponential moving average [4] 如下式所示
$$
s_t = \alpha x_t + (1-\alpha)s_{t-1} = \alpha\sum_{k=0}^{\infty}(1-\alpha)^kx_{t-k}
$$
其中 $x_t$ 为 $t$ 时刻新的样本,$s_t$ 为 $t$ 时刻累积样本,可以看出历史数据是以指数级别衰减,即随着 k 增大,而在最终结果中占比降低。probe无论空间,还是方向上,都是相对比较稀疏的分布,因此八面体一个cell会占据半球面上相当大的区域。
作者发现这种方式会明显损失真实感。相反,作者选择将新得到的光线样本radiance与重建的radiance之间的标准化差异作为temporal blending amount的一个因素。下面是blend过程的算法伪代码。
1 | |
上述算法以图像一定程度的变暗为代价,更好了保留了遮挡与阴影。除此之外,该算法还有荧光点去除的作用,过滤掉比八面体cell对应的立体角小得多的明亮信号,提高时序稳定性。
另一点,由于guiding策略,会有部分cells不存在任何样本,这时如果直接重用时序重建的结果会导致明显的视觉artifact,然后对这些cells直接留空又会由于能量损失而过暗。对此,作者选择对已填充cell的radiance进行平均,并均匀分布到未追踪的cell中。这种做法是通过近似缺失的样本来恢复一些丢失的能量,如 Fig-6 所示。在测试中,这种情况只会应用到低概率cell上,同时没有发现明显的visual artifacts。
这种情况的处理,非常trick。仅仅是求其他所有光追样本的平均值,作为没有追踪的cell的近似样本。

2.1.5 Probe Masking
probe是放置在 8x8 screen tiles内的任意一个像素上,因此使用 32-bit 整数编码 tile 内的像素坐标,来确定probe位置。该整数使用一张2D贴图存储 probe_mask。对于empty tile或者无效tile,使用一个 sentinel value 表示,如 Fig-7 所示。

在运动中,有大量区域缺失probe。在采样probe时,通常需要查找某一方向上最近的probe。作者提出生成 probe_mask 的 mip chain 来实现高效查找最近的有效probe,其中 mip chain 维护了上一层 2x2 中第一个找到的有效probe。查找像素给定方向上的最近有效probe的算法如下所示
1 | |
2.1.6 Probe Filtering
由于probe的光线样本在八面体cell内每帧都会抖动,以及后面提出的hash cell返回的radiance也会很噪,因此导致probe非常噪。作者使用前一小节的高效搜索算法,再执行一次 7x7 稀疏blur。filter 算法伪代码如下所示,其中再次用到了 cell_size 来排除掉较远的probe以及避免light leaking。
1 | |
注意:前面的ray guiding策略,会导致cell上对应的光线样本可能属于其它cell,但后续处理已经将每个cell的radiance结果处理到对应位置,因此上述算法仅仅对不同probe之间对应的cell进行filter。
算法最后使用了与 [2] 相似的角度误差检测方法,用来保留一些小尺度的遮挡细节,如图 Fig-8。

2.1.7 Adaptive Cell Size
前面这些小节多次用到了cell_size,这个量直接关系到相邻probe之间的radiance重用对空间误差的容忍度。cell_size 的值越小能够保留更好的细节,但时序稳定性差,越大能有更好的时序稳定性,但降低光照质量。作者提出使用基于与相机的距离,自适应调整 cell_size,效果如 Fig-9 所示。

自适应调整 cell_size 的算法伪代码如下,其中 fov_y 为垂直 fov,单位为radians;proj_size 是投影后cell size,单位为像素,作者选择 8.0,即相邻probe之间粗略的像素距离。此外,distance_scale 在每帧是固定,可以在 CPU 上计算好。
1 | |
2.1.8 Persistent Least-Recently Used (LRU) Side Cache
对于具有细小几何特征的情况下,会出现probe的时序-空间的radiance重用一直失败的情况,从而导致时序上的不稳定性。例如 Fig-10 中,一个tile内的细小几何特征,有如下过程:
第一帧 probe 1 生成在细小的几何特征上,并计算probe数据
第二帧 probe 2 (同一tile内)生成,但由于 cell_size 测试失败,无法重用来自上一帧 1 的信息。因此,它需要从头开始重新计算(在忽略掉 3x3 邻域重建过程的情况下)。
这里的cell_size测试失败不理解,感觉更多是 probe 2 不在细小几何特征上,normal测试或者 probe 2 所在位置失效导致失败
第三帧 probe 3 重新生成在几何特征上,因此同样无法重用上一帧 2 的信息
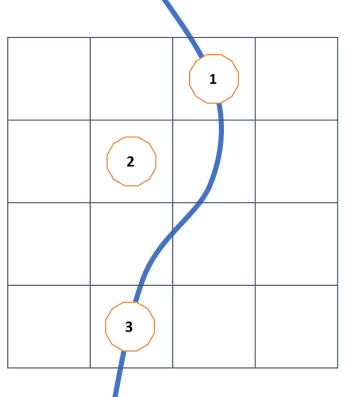
上述情况中,probe 3 可以重用 probe 1 的信息,但由于 probe 2 由于重用失败,导致 probe 1 的信息已经被覆盖。因此在这种情况下,该tile内的时序重投影、ray guiding以及blending在每帧一直处于失败状态。作者提出使用一个 LRU queue 来维护被逐出的 (evicted) probe,这样就可以让这些probe能在任意帧后被使重用。当新生成的probe无法从同一tile的重投影probe中复用数据时,则尝试重用queue中的cache probe。
queue中存储的是cache probe的索引,其数据存储在贴图中索引对应位置。由于cache probe可能会存在很多帧,无法使用depth buffer还原其世界坐标。因此需要为每个cache probe保存 float3 position 以及编码到单个 float 中的world normal,作者使用 128-bit integer存储。
在 2.1.3 小节的guiding策略前,需要 3x3 probe space 的半球重建。在这里,更新该半球重建过程为完成 3x3 重投影 tile 搜索后,再在 3x3 相邻 tile 上搜索 cache probe。与之前一样,radiance进行视差矫正并累积到 LDS 中。当完成搜索后,side cache 的更新有三种情况:
当前一帧probe被新生成probe逐出且无有效cache entry时,创建一个新的cache entry,并在blending pass将重投影radiance更新到cache。
上一帧probe被当前帧逐出,也就是说重投影失败。在blending pass写入cache应该是指重投影radiance以blend形式写入。
当前一帧被新生成probe逐出且找到匹配cache entry,在blending pass将重投影radiance写入cache,并将该cache entry放入 most-recently used (MRU) queue。
无论前一帧probe是否被逐出,都会识别参与重建的最匹配cache entry。如果有的话,则在blending pass将重投影radiance写入cache,这可以确保cache数据不会落后于光照状态改变。
在cache中查找匹配cache entry,是在 3x3 相邻 tile 上进行的。如前所述,先将cache entry投影到屏幕,判断哪些位于 3x3 相邻tile。其中最匹配的cache entry的数据会被更新,这应该包括了第二种情况
每帧还要执行 re-ordering pass,将 MRU 中的cache entries永远放在LRU queue最前面。上述情况中,更新cache entry需要使用 atomic compare and swap,避免多个work groups在radiance blending阶段同时更新同一cache。
2.2 World Cache
world cache 维护了次级光路顶点的出射radiance(按照forward path tracing的方向来看),作者基于 [5] 中的 hash cells 数据结构,提出新的 tiling 方法,该方法能够更高效地在相邻cells之间filter。
2.2.1 Caching Outgoing Radiance for Secondary Path Vertices
world cache通过对顶点描述的hash来寻址hash table中的radiance cell。寻址过程如下图所示,先使用一个fast hash定位bucket index;再使用另一个hash函数计算一个fingerprint,用于在bucket内 linear probing,确定cell的存储位置。作者选择了两个彼此之间几乎不会冲突的hash函数,即linear probing过程不会比较顶点描述,而是直接比较第二次hash生成fingerprint,忽略了第二次hash冲突的可能性。

作者构建的顶点描述包含:
- 顶点坐标、光线方向:邻近顶点间的重用与filter
- 层级:
- 光线长度与cell_size的比较结果
每个cell还会关联一个衰减值decay,用于管理cell entry的生命周期。在每次访问cell时都会重置decay,否则就会持续衰减,如果一个cell的decay到0,则释放cell entry。hash table的主要瓶颈来自于大量使用atomic,例如每次插入,这可以通过存储下来顶点的查找结果来避免。
2.2.2 Eliminating Light Leaks
在与周围顶点进行filter时,会存在light leaking异常效果,如下图所示情况。遮挡边缘的两个相邻顶点,离得近,同时secondary ray的方向接近评选,导致descriptor经过hash后落入同一cell。这种情况下,相邻顶点的filter会导致漏光
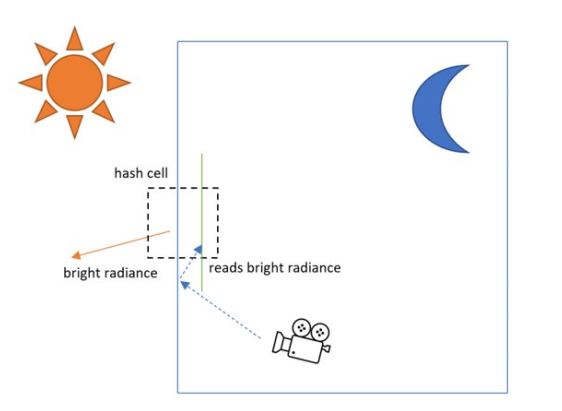
作者发现这类light leaking大部分出现在次级光线长度小于要查找cell大小的情况下,也就是光线没有离开cell。对于此,向descriptor中加入比较结果 (ray_length < cell_size),可以避免这种情况发生。
2.2.3 Prefiltering Radiance
cell之间filter需要访问 3x3x3 相邻cell,但在hash space的开销非常大。作者提出 two-level 数据结构,其中 cell 被组织到 tile 内,bucket 中索引的是tile,cell由tile内的局部坐标来索引,如下图所示。

每个tille表示了场景固定大小的区域,相当于一个比较大的voxel,但tile中的cell在三维空间下是相对稀疏的,同时小范围的表面接近于二维平面,因此作者选择将cell投影到2D tile上的方式,将cell向最大outgoing方向的轴向投影。
最大outgoing方向应该是值tile内所有cell的所有光线方向取最大
tile 是一个超大的voxel,被hash table索引。cell是tile内连续的小voxel,按照局部位置连续排放。这也意味着tile需要更大的存储空间。对于 3x3x3 cells 的filter,如果没有这么多相邻cells呢?
这种做法以不高的存储开销,使得tile之内相邻cell之间filter操作更加高效,但tile之间仍然无法解决,作者选择依赖于screen cache来掩盖这部分偏差。
将方差降低到可接受的水平通常需要cell内几帧的累积。对于时序累积,第一层 mip level 使用 exponential moving average [4] ,后续层级都是上一层级使用box filter。在实现中,作者选择 8x8 tile size,这样性能最佳。最终,通过查询第一层,累积radiance到screen cache。
2.2.4 Evaluating Lighting at Secondary Path Vertices
前面描述了如何在two-level hash数据结构中缓存和filter次级路径顶点的直接光照。但直接光照仍然需要计算。首先执行重投影,如果重投影成功则复用上一帧的光照;否则,需要计算顶点光照着色,这是 Light Sampling 小节的内容。
对于重用的上一帧radiance样本,既包含了直接光照,又包含了间接光照。这种重用会为当前帧带来多一次间接路径,近似无限反弹,称为 temporal radiance feedback。
但cell中的顶点只有直接光照,并没有间接光照。从PPT里看到,这里的重投影是在屏幕上执行的,即将顶点重投影到上一帧,看是否在屏幕上,在屏幕上则重投影成功,否则重投影失败。也就是world cache本身无法做到无限反弹,只有屏幕上看到的顶点具有无限反弹。
无限反弹过程:
- 第一帧
- screen probe光追得到hash cell顶点,hash cell计算一次反射点的直接光
- screen probe从hash cell得到一次反射间接光
- 计算屏幕的直接光照,从screen probe得到的一次反射间接光
- 第二帧
- screen probe光追得到hash cell顶点
- hash cell顶点重投影成功,得到其上一帧的直接光照与一次反射间接光。hash cell顶点作为一次反射点,意味着属于当前帧的一次反射间接光、二次反射间接光
- hash cell顶点重投影失败,计算其直接光照,即一次反射间接光
- screen probe从hash cell得到间接光,此时融合了二次反射间接光
- 计算屏幕像素的直接光照,从screen probe采样间接光,这里采样得到的最多反射是二次反射
- 第三帧:最大三次反射
因此无限反弹只有部分cell顶点具有。
2.3 Light Sampling
hit points 的着色
2.3.1 Reservoir-based Resampling
2.3.2 Light Grid Lookup Structure
2.4 Irradiance Estimation
本小节使用probe数据评估屏幕像素的 irradiance。
2.4.1 Per-Pixel Interpolation
使用像素周围的probe进行加权平均来重建像素光照。使用 2.1.5 小节定义的 find_closest_probe 函数查找四个方向上相邻probes,基于表面深度、normal的edge-aware function的权重设计。同样使用 cell_size 排除掉远离的probe,即赋予权重 0。
对于周围4个probe权重都为0或很小的情况,使用均值代替。
除此之外,在查找相邻probe之前,会先抖动像素位置,这样可以打破 structured artifact,但当抖动位置远离原像素所在平面时,则取消这次抖动。
2.4.2 Spherical Harmonics
在评估irradiance时,通常需要提取所有附近的radiance样本。更好的方式是在插值之前,先将probe投影到SH,SH 具有以下优点:
- 只使用前三阶可以过滤掉高频噪声
- 能够以低存储开销较好地表示 irradiance
- reprojection pass 可以只重投影 SH
2.4.3 Denoising
自适应blur
Reference
[1] Boissé, G. and Meunier, S. 2022. GI-1.0: A Fast Scalable Two-Level Radiance Caching Scheme for Real-Time Global Illumination.
[2] Daniel Wright. 2021. Radiance Caching for Real-Time Global Illumination. https://advances.realtimerendering.com/s2021/index.html#_mrnver3hf0ag
[3] Zina H. Cigolle, Sam Donow, Daniel Evangelakos, Michael Mara, Morgan McGuire, and Quirin Meyer. 2014. A Survey of Efficient Representations for Independent Unit Vectors. Journal of Computer Graphics Techniques (JCGT) 3, 2 (17 April 2014), 1–30. http://jcgt.org/published/0003/02/01/
[4] Brian Karis. 2014. HIGH-QUALITY TEMPORAL SUPERSAMPLING. http://advances.realtimerendering.com/s2014/#_HIGH-QUALITY_TEMPORAL_SUPERSAMPLING
[5] Binder, N., Fricke, S., and Keller, A. 2021. Massively Parallel Path Space Filtering.