GPU Logic
1 Life of triangle [1]

1.1 GPUs are super parallel work distributors
为什么需要这些复杂性?在图形渲染中,我们需要处理数据扩展 (data amplification) 的问题,这会带来大量不确定的工作负载。每个 draw call 可能生成不同数量的三角形。裁剪后的顶点数量可能与最初的三角形数量不同。在背面剔除和深度剔除之后,不同的三角形可能生成不同的像素。
因此,现代GPU让它们的基本图元(三角形、线、点)遵循的是逻辑流水线,而不是物理流水线。在早期(G80统一架构之前,如DX9硬件、PS3、Xbox360),流水线在芯片上通过不同的阶段体现,工作依次通过这些阶段处理。G80架构基本上对部分单元进行了复用,可以根据负载在顶点着色器和片段着色器之间切换,但仍然以串行方式处理图元、光栅化等。而从Fermi架构开始,流水线变得完全并行,这意味着芯片通过复用多个内部引擎实现了逻辑流水线(即三角形经过的各个步骤)。
假设有两个三角形A和B。它们可能处于不同的逻辑流水线步骤中。例如,A已经被变换,正在进行光栅化。一些像素可能在执行fragment shader,一些像素可能被深度缓冲剔除(Z-cull),还有一些像素可能已经写入帧缓冲区,而还有一些可能仍在等待。同时,三角形B可能在提取顶点数据。因此,尽管每个三角形都需要经过这些逻辑步骤,但许多三角形生命周期的不同阶段可以同时被处理。整个draw call任务被拆分为许多较小的任务,甚至是子任务,这些任务可以并行运行。每个任务都会根据可用的资源进行调度,这种调度不限于某种特定类型的任务(例如顶点着色和片段着色可以并行进行)。
可以把这想象成一条分叉的河流。并行的pipeline stream是彼此独立的,每条pipeline都有自己的时间线,有些pipeline可能分支更多。如果我们用颜色对GPU中的单元进行编码,标记它们当前正在处理的三角形或draw call,那么整个系统就会像一片多彩的“闪烁灯”景象 :)
1.2 GPU architecture

由于 Fermi 架构的 NVIDIA GPU 拥有相似的基本架构设计,其中核心部分是一个管理所有任务的 Giga Thread Engine。GPU 被划分为多个 GPC(Graphics Processing Cluster,图形处理簇),每个 GPC 包含多个 SM(Streaming Multiprocessor,流式多处理器) 和一个 Raster Engine(光栅引擎)。在这些组件之间有大量的互联结构,其中最为重要的是 Crossbar(交叉开关),它允许任务在 GPC 或其他功能单元(例如 ROP(Render Output Unit,渲染输出单元) 子系统)之间迁移。
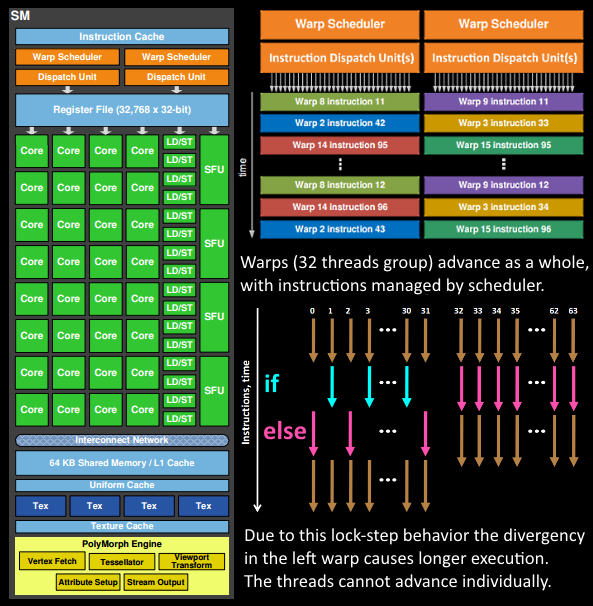
程序员编写的任务(例如着色器程序的执行)实际上是由 SM 来完成的。SM 包含许多 Core(核心),这些核心负责执行线程的数学运算。例如,一个线程可以对应于一个顶点着色器或像素着色器的调用。这些核心以及其他单元由 Warp Scheduler(Warp 调度器) 驱动,每个 Warp 调度器管理一组 32 个线程(称为一个 Warp),并将需要执行的指令交给 Dispatch Unit(分发单元)。指令的逻辑由调度器处理,而核心本身并不负责逻辑计算。核心接收到的指令类似于““sum register 4234 with register 4235 and store in 4230”。相比之下,GPU 的核心显得相对“简单”,而 CPU 的核心则更“智能”。GPU 将智能设计集中在更高的架构层面,协调整个系统(甚至多个系统)的工作。
GPU 上这些单元的具体数量(例如每个 GPC 包含多少个 SM,每个 GPU 有多少个 GPC)取决于具体的芯片配置。
1.3 The logical pipeline
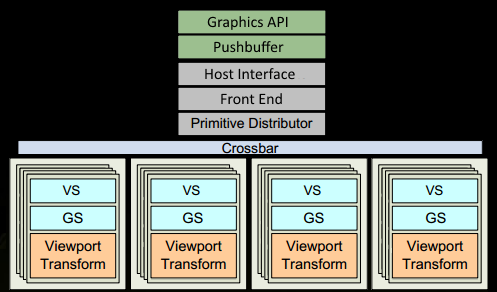
为简化起见,省略了一些细节。我们假设 drawcall 引用了一些已经填充好数据的 index- and vertex-buffer,这些缓冲区存储在 GPU 的 DRAM 中,并且仅使用 VS 和 PS:
程序在图形 API中发起 drawcall。该调用最终会到达驱动程序,驱动程序对调用进行一些合法性验证,并将命令以 GPU 可读取的编码形式插入到 pushbuffer(推送缓冲区) 中。在此过程中,CPU 端可能出现许多瓶颈,因此程序员需要合理使用 API,并采用能充分利用现代 GPU 性能的技术。
一段时间后或显式的“flush”调用,驱动程序在 pushbuffer 中积累了足够的工作量,将其发送给 GPU 进行处理(这一过程可能需要操作系统的部分参与)。GPU 的 Host Interface(主机接口) 接收到这些命令,并通过 Front End(前端) 进行处理。
接着,工作分发开始于 Primitive Distributor(图元分发器),通过处理 index buffer 中的索引数据生成三角形工作批次,并将其分发到多个 GPC。
在 GPC(图形处理簇) 内,一个 SM(流式多处理器) 的 Poly Morph Engine(多边形形变引擎) 负责从三角形索引中提取顶点数据(即Vertex Fetch)
完成顶点数据的提取后,SM 内会调度一个由 32 个线程组成的 Warp(线程束) 来处理这些顶点数据。
SM 的 Warp 调度器(Warp Scheduler) 会按照顺序为整个 Warp 发出指令。这些线程以 lock-step 执行每条指令,但如果某些线程无需执行某条指令,则它们可以被单独屏蔽。屏蔽线程的情况可能包括:
- 例 1:当前指令属于 “if (true)” 分支,但某个线程的数据条件计算结果为 “false”;
- 例 2:某个线程已经满足了循环终止条件,而其他线程尚未满足。
因此,当着色器中出现大量分支分歧(branch divergence)时,将显著增加 Warp 中所有线程的执行时间。
需要注意的是,线程无法独立推进,它们只能以 Warp 为单位共同推进!不过,Warp 之间是相互独立的。
Warp 的一条指令可能一次完成,也可能需要多个调度周期。例如,在 SM 中,处理 load/store 操作的单元通常比处理基本数学运算的单元要少。
由于某些指令(特别是内存加载)需要更长的时间来完成,Warp 调度器 会切换到其他不需要等待内存的 Warp。这正是 GPU 克服内存读取延迟的关键机制:通过切换warp,隐藏延迟并减少等待时间。为了实现快速切换,调度器管理的所有线程在 寄存器文件(register file) 中拥有各自独立的寄存器。如果某个着色器程序需要的寄存器较多,那么可容纳的线程/Warps 就会减少。这意味着可供切换的 Warp 也减少,从而在等待指令完成(尤其是内存加载)期间,可执行的有效工作量也会减少。这种寄存器资源的限制可能会导致效率下降。
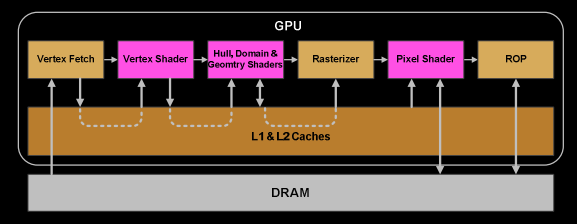
当 Warp 完成所有顶点着色器的指令后,其结果将由 视口变换 进行处理。随后,三角形将在 clip space volume 内进行裁剪,准备进入光栅化阶段。 在这一过程中,我们使用 L1 缓存 和 L2 缓存 来存储并管理各个任务之间通信的数据。
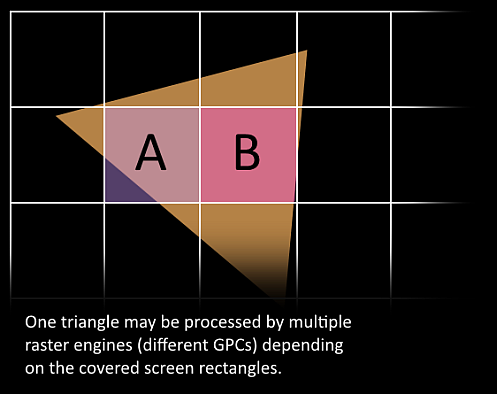
现在到了令人兴奋的部分,我们的三角形即将被分解,并可能会离开当前所在的 GPC(图形处理簇)。三角形的 bounding box 被用来决定哪些**光栅引擎(raster engines)**需要对其进行处理,因为每个光栅引擎负责屏幕上的多个 tile(瓦片)。 随后,三角形通过 Work Distribution Crossbar 被发送到一个或多个 GPC。此时,我们有效地将三角形分解成许多更小的任务进行处理。
在目标 SM 内的 Attribute Setup(属性设置) 阶段,会确保插值数据(例如在顶点着色器中生成的输出数据)被转换为适合像素着色器的格式。
GPC(图形处理簇) 的 Raster Engine 会处理其接收到的三角形,为其负责的区域生成像素信息,并执行背面剔除和深度剔除操作。
接着,我们将像素处理任务按 32 个线程(即 8 组 2x2 像素块,quad)进行批处理。这种 2x2 像素块 是像素着色器的最小处理单位。这种划分方式允许我们计算一些导数,例如用于纹理的 MIP 映射过滤(当像素块内的纹理坐标变化剧烈时,选择更高层级的 MIP)。对于那些 2x2 像素块中采样位置并未实际覆盖三角形的线程,将会被屏蔽(例如通过 gl_HelperInvocation)。然后,像素着色任务将交由本地 SM 的某个 Warp 调度器进行管理。
像素着色线程在 Warp 调度器 中执行的调度逻辑,与顶点着色器阶段的类似。线程仍然以锁步(lock-step)方式运行,这种方式特别有用,因为它可以高效访问 像素块 内的数值(几乎零成本),因为所有线程的数据都保证在同一指令点完成计算(通过扩展如 NV_shader_thread_group 实现)

我们完成了吗?快了!
像素着色器已经完成了颜色的计算,并生成了需要写入 Render Targets 的深度值。在将这些数据交给 ROP(Render Output Unit) 子系统之前,我们需要考虑三角形的原始 API 排序(像
gl_PrimitiveID?)。这是因为 ROP 子系统 本身包含多个 ROP 单元,在其中执行深度测试、与 Framebuffer 的 Blending 等任务。这些操作必须是原子性的(Atomic,一次只能处理一组颜色和深度值),以确保当两个三角形覆盖同一个像素时,不会出现一个三角形的颜色与另一个三角形的深度值相结合的情况。
此外,NVIDIA 通常会应用内存压缩技术(Memory Compression)来降低对内存带宽的需求,从而提升“有效”带宽(详见 GTX 980 的 PDF 文档)。
终于完成了!
我们已经成功将像素写入到渲染目标中。希望这部分信息能帮助您了解 GPU 内部的工作流和数据流。同时,这也可以帮助您理解为何与 CPU 的同步操作会对性能造成如此大的影响。
当 GPU 必须等待所有任务完成且没有新的工作提交时,所有硬件单元都会变为闲置状态(Idle)。当发送新的工作任务时,整个 GPU 从完全闲置状态到再次完全负载需要一些时间,尤其是对于那些规模较大的 GPU。
在下面的图片中,您可以看到一个 CAD 模型的渲染结果,其中不同的颜色表示了对图像贡献的不同 SM(流式多处理器) 或 Warp ID。需要注意,这种结果通常是帧间不一致的(Frame-Coherent),因为工作分配会在每一帧之间有所变化。这幅场景使用了许多 Draw Calls 渲染完成,其中一些可能是并行处理的(通过 NSIGHT 工具可以观察到这种 Draw Call 的并行性)。

2 The Peak-Performance-Percentage Analysis Method for Optimizing Any GPU Workload
这篇博客介绍基于硬件指标 (hardware metrics) 的性能分析方法,帮助我们了解整个GPU的使用情况,哪些硬件单元或子单元限制了性能,以及它们的运行效率多大程度接近各自的最大吞吐量 (maximum throughput,也成为 Speed of Light SOL)。假设应用程序没有使用异步计算或异步复制队列,那么这种硬件为中心的信息可以映射回图形 API 和着色器的操作,进而为提升任何给定工作负载的 GPU 性能提供指导,如图 1 所示:
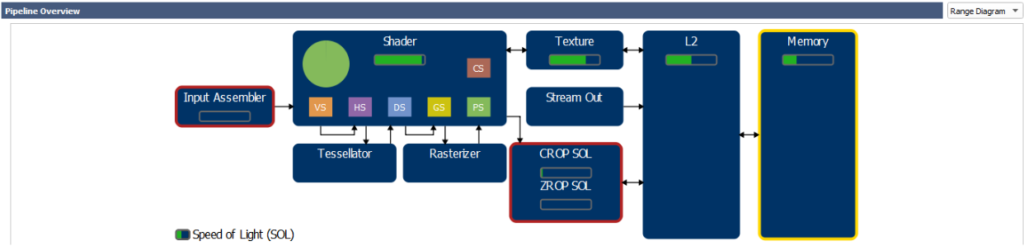
- 如果没有任何 GPU 单元的吞吐量接近其最大吞吐量(SOL),那么我们会努力提高至少一个单元的实际吞吐量。
- 如果某个 GPU 单元的吞吐量已经接近其最大吞吐量(SOL),那么我们会找出如何从该单元中移除部分工作负载。
这些硬件metrics可以使用 Nsight Graphics 的 range profiler 捕获。
2.1 step1: Capturing a Frame with Nsight Graphics
2.2 step 2: Breaking Down the GPU Frame Time
2.3 step 3: Profiling a GPU Workload
2.4 step 4: Inspecting the Top SOLs & Cache Hit Rates
2.4.1 The Per-Unit SOL% Metrics
在分析工作负载时,首先要关注的是GPU每个单元的SOL%,可以理解为实际吞吐量与理论吞吐量的比值。然而,对于具有多个子单元或并行数据路径的单元,SOL% 表示所有子单元和数据路径的子 SOL 指标中的最大值。GPU 各个单元有:
- PD (Primitive Distributor):加载 index-buffer,并分发图元到芯片各处(GPC,Graphics Processing Cluster)
- VAF (Vertex Attribute Fetch):在vertex shader启动前,加载 vertex-buffer
- SM (Streaming Multiprocessor):执行 shader
- TEX:执行 SRV (shader resource view) 提取操作,以及 UAV (unordered access view,读写) 访问
- VPC (Viewport Culling):负责视口变换、视锥剔除以及属性的透视矫正
- L2:每个 VRAM 分区附带的二级缓存
- CROP:负责对渲染目标进行颜色写入和混合操作
- ZROP:负责深度和模板测试
- VRAM:GPU 显存
现代 GPU 并不是一个简单的线性流水线(A→B→C→……),而是由互联单元组成的网络(如 SM↔TEX↔L2,SM→CROP↔L2 等)。简单的“瓶颈”计算方法(基于每个单元的固定上下游接口)不足以全面分析 GPU 性能。因此,在进行性能分析时,我们主要关注每个单元的 SOL% 指标,以确定限制性能的单元和/或问题。下一部分将详细讨论这一方法。
2.4.2 The “Top SOL Units”
先从 TOP-5 SOL 入手
2.4.2.1 最高 SOL% > 80%
如果最高 SOL% 大于 80%,这表明对应工作负载在 GPU 上运行得非常高效(接近最大吞吐量)。要进一步提高速度,可以尝试减少最高 SOL 单元的工作量,或者将其部分任务转移到其他单元。例如:
- 如果TOP SOL 单元是 SM,且 SOL% > 80%,可以尝试优化掉一些指令组,或将某些计算转换为lookup table。
- 对于受到纹理吞吐量限制的工作负载 (因为结构化缓冲区通过 TEX 单元加载),可以考虑将 structured buffer 的加载转移为 constant buffer 加载 [4],尤其是当着色器对 structured buffer 的访问是统一(uniformly)的 (所有线程从同一地址加载数据时)
2.4.2.2 最高 SOL% < 60%
如果最高 SOL% 小于 60%,这表明最高 SOL 单元以及所有 SOL% 更低的 GPU 单元存在以下问题:
- 利用率不足(空闲周期较多)
- 运行效率低下(阻塞周期较多)
- 未充分利用快速路径,原因在于分配的工作负载特性
以下是一些具体的例子:
- 应用程序部分受到 CPU 限制(见第 5.1.1 节)。
- 大量的
Wait For Idle命令或graphics与compute模式频繁切换,导致 GPU 管道反复清空(见第 5.1.2 节)。 - TEX 从某些纹理对象提取数据,由于其格式、维度或过滤模式的设计限制,运行吞吐量降低。例如,当trilinear采样 3D 纹理时,TEX SOL% 为 50% 是正常的
- 内存子系统效率低下,包括:
- TEX 或 L2 单元的缓存命中率较低
- 稀疏的 VRAM 访问导致 VRAM SOL% 偏低
- VB(顶点缓冲区)、IB(索引缓冲区)、CB(常量缓冲区)或 TEX(纹理)从系统内存而非 GPU VRAM 获取数据
- 输入装配阶段提取 32 位索引缓冲区(与 16 位索引相比,效率减半)
注意:在这种情况下,我们可以使用最高 SOL% 值来估算通过减少低效因素所能达到的性能提升上限。例如,如果某工作负载的 SOL 当前为 50%,假设通过优化内部低效可以将 SOL 提高到 90%,则该工作负载的最大性能增益为 90/50 = 1.8 倍 = 80%。
2.4.2.3 最高 SOL% 位于 [60%, 80%]
这种情况需要结合以上两种情况分析。
2.4.3 Secondary SOL Units and TEX & L2 Hit Rates
Nsight Range Profiler 报告前 5 个最高 SOL 单元而不仅仅是最高的一个,原因在于多个硬件单元可能会相互影响,并在一定程度上共同限制性能。因此,我们建议根据 SOL% 值手动对 SOL 单元进行聚类。
(在实践中,10% 的差距通常是定义这些聚类的合理范围,但为了不遗漏任何问题,建议手动完成聚类分析。)
我们还建议查看 TEX(L1 缓存)和 L2 缓存的命中率,这些数据可以在 Range Profiler 的“Memory”部分中找到。一般来说:
- 命中率大于 90% 表示很好
- 70% ~90% 表示较好
- 而低于 70% 则较差(可能会显著限制性能)。
2.4.3.1 示例1:full-screen HBAO+ blur
full-screen HBAO+ blur 的 top 5 SOL 单元:
| SM:94.5% | TEX:94.5% | L2:37.3% | CROP:35.9% | VRAM:27.7% |
|---|
注意,这个工作负载同时受到 SM 和 TEX 的限制。由于 SM 和 TEX 的 SOL% 值完全相同,可以推测 SM 的性能可能受到 SM 和 TEX 单元之间接口吞吐量的限制(可能是 SM 向 TEX 的请求,或者 TEX 返回数据到 SM 的过程)。
该工作负载的 TEX 缓存命中率为 88.9%,L2 缓存命中率为 87.3%。
有关此工作负载的详细分析,请参考附录 “TEX-Interface Limited Workload”
2.4.3.2 示例2:SSR
| SM:49.1% | L2:36.8% | TEX:35.8% | VRAM:33.5% | CROP:0.0% |
|---|
在这个工作负载中,SM 是主要瓶颈,而 L2、TEX 和 VRAM 是次要限制因素。TEX 缓存命中率为 54.6%,L2 缓存命中率为 76.4%。
较低的 TEX 命中率可以解释 SM 的低 SOL% 值:由于 TEX 命中率较低(很可能是因为相邻像素访问了相距较远的纹素),SM 观察到的平均 TEX 延迟高于正常值,且更难以掩盖延迟。
注意:在这种情况下,活跃单元实际上构成了一条依赖链:SM -> TEX -> L2 -> VRAM。
2.4.3.3 示例3:tiled-lighting compute shader
| SM:70.4% | L2:67.5% | TEX:49.3% | VRAM:42.6% | CROP:0.0% |
|---|
这个工作负载中,SM 和 L2 是主要限制因素,而 TEX 和 VRAM 是次要限制因素。TEX 缓存命中率为 64.3%,L2 缓存命中率为 85.2%。
2.4.3.4 示例4:shadow-map generation
| PD:31.6% | VRAM:19.8% | VPC:19.4% | L2:16.3% | VAF:12.4% |
|---|
这个工作负载受到 PD(图元分发器) 的限制,且最高 SOL% 较低。在这种情况下,将索引缓冲区的格式从 32 位更改为 16 位显著提升了性能。
由于 TEX 并未出现在前 5 个 SOL 单元中,因此 TEX 命中率无关紧要。而 L2 缓存命中率为 62.6%。
2.5 step 5: Understand the Performance Limiters
我们现在需要了解是什么限制了这些top-SOL单元的性能。
2.5.1 If the Top SOL% is Low
一个工作负载可能同时受到多种病理问题的影响。下面检查以下指标的值:“Graphics/Compute Idle%” 和 “SM Active %”。
2.5.1.1 The “Graphics/Compute Idle%” metric
“Graphics/Compute Idle%” 是指在当前工作负载中,整个图形与计算硬件管线完全空闲的 GPU 总运行周期百分比。这些周期表示图形/计算管线为空的时间,可能是因为以下原因之一:
- CPU 无法足够快地向 GPU 提供指令。
- 应用程序正在使用同步 Copy Engine(这可能发生在 DIRECT 队列或即时上下文中调用 Copy 操作时)。
**注意:**由于 Wait For Idle 命令导致的管线清空不计入 “Graphics/Compute Idle”
在这种情况下,我们建议测量每个工作负载中以下 CPU 调用所消耗的总 CPU 时间,并尝试优化最耗时的部分:
- 对于 DX11
Flush{,1}MapUpdateSubresource{,1}
- 对于 DX12:
WaitExecuteCommandLists
- 适用于 DX11 和 DX12:所有的
Create或Release调用
DX11 注意事项:
ID3D11DeviceContext::Flush- 调用
Flush强制启动命令缓冲区,可能导致 CPU 等待。
- 调用
ID3D11DeviceContext::Map(针对 STAGING 资源)- 如果连续帧中映射了相同的 STAGING 资源,可能因资源争用导致 CPU 阻塞。在这种情况下,当前帧的
Map调用必须等待之前帧的处理完成。
- 如果连续帧中映射了相同的 STAGING 资源,可能因资源争用导致 CPU 阻塞。在这种情况下,当前帧的
ID3D11DeviceContext::Map(使用 DX11_MAP_WRITE_DISCARD)- 如果驱动程序耗尽了版本化空间(versioning space),
Map调用可能导致 CPU 阻塞。因为每次Map(WRITE_DISCARD)调用都会从固定大小的内存池返回一个新指针。当内存池耗尽时,Map调用会等待。
- 如果驱动程序耗尽了版本化空间(versioning space),
DX12 注意事项:
ExecuteCommandLists(ECL)调用- 每次
ECL调用都存在一些与启动新命令缓冲区相关的 GPU 空闲开销。 - 为减少 GPU 空闲时间,建议将所有命令列表批处理为尽可能少的
ECL调用,除非需要在帧的某些点强制启动命令缓冲区(例如,在 VR 应用中减少输入延迟,保持单帧在飞行状态时)。
- 每次
ID3D12CommandQueue::Wait调用- 当应用调用
Wait等待某个栅栏时,操作系统(Windows 10)会暂停向该命令队列提交新命令缓冲区,直到Wait调用返回。
- 当应用调用
**注意:**通过 Nsight 可以测量每个 API 调用的 CPU 和 GPU 时间,这些数据会在每次启动 Range Profiler 时显示在 API 统计视图中。
2.5.1.2 The “SM Active%” metric
2.5.1.3 GPU Trace
2.5.2 If the Top SOL Unit is the SM
2.5.2.1 Case 1: “SM Throughput For Active Cycles” > 80%
2.5.2.2 Case 2: “SM Throughput For Active Cycles” < 60%
2.5.2.3 Case 3: SM Throughput For Active Cycles % in [60,80]
2.5.3 If the Top SOL unit is not the SM
2.5.3.1 If the Top SOL unit is TEX, L2, or VRAM
2.5.3.2 If the Top SOL unit is CROP or ZROP
2.5.3.3 If the Top SOL unit is PD
2.5.3.4 If the Top SOL unit is VAF
3 Optimizing VK/VKR and DX12/DXR Applications Using Nsight Graphics: GPU Trace Advanced Mode Metrics
3.1 Capturing GPU Trace data with Advanced Mode Metrics
Reference
[1] https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline
[2] https://developer.nvidia.com/blog/the-peak-performance-analysis-method-for-optimizing-any-gpu-workload/
[3] https://developer.nvidia.com/blog/optimizing-vk-vkr-and-dx12-dxr-applications-using-nsight-graphics-gpu-trace-advanced-mode-metrics/
[4] [Structured Buffer Performance](./Structured Buffer Performance.md)