1. Nanite - Introduction
1 Summary
cluster:提高顶点重用
gpu-driven:CPU只需要提交场景变化,而GPU完成遮挡剔除,组织绘制指令,减少CPU提交绘制指令开销以及同步开销
LOD:传统的LOD是根据物体到相机距离切换,容易出现跳变。基于有向无环图的LOD的生成过程以 cluster group 为单位,即模型的一小部分。切换LOD也是以 cluster group 为单位。
- 先预处理场景几何,切分为cluster单位。
- 再将一定数量的相邻cluster合并为cluster group
- 对 cluster group 简化,生成高LOD的cluster。简化过程需要锁边界,保证简化后,cluster group之间不会出现空隙。
除
2.1 视锥剔除
判断物体的包围盒与视锥体的关系。将物体包围盒投影到NDC空间,判断是否与视锥有交集
2.2 遮挡剔除
用于剔除被更近的不透明物体遮挡的物体。对物体的遮挡剔除同样使用其包围盒,投影到NDC空间,通过查询 depth buffer 判断是否被遮挡。
物体的包围盒投影到NDC空间,会形成一个区域,如果对区域内每个像素进行深度测试,会比较费。常见做法是,depth buffer 生成 HZB,高层级存储低层级对应4个像素中最远的深度。同时,基于包围盒投影的区域来选择要查询的层级,包围盒在该层级会投影为一个点。此时选择比较投影点bilinear 区域的4个像素,这样就能保守地包括住整个包围盒。
3 LOD
3.1 基于 DAG 的 LOD 选择
给定相机位置和参数,如何对某个可见实例对应的网格进行 LOD 选择 ,以选出合适的三角形簇进行渲染 ?
- 要保证模型上不会有空隙、不会有重叠
- 不出现重叠:本质上是要求DAG从叶节点到根节点的每条路径上至多有一个节点被选中。只要叶节点向上的路径,误差是单调不减。
- 不出现空隙:本质上是要求DAG从叶节点到根节点的每条路径上至少有一个节点选中。令叶节点误差为0,根节点误差为无穷,一定会选中一个节点
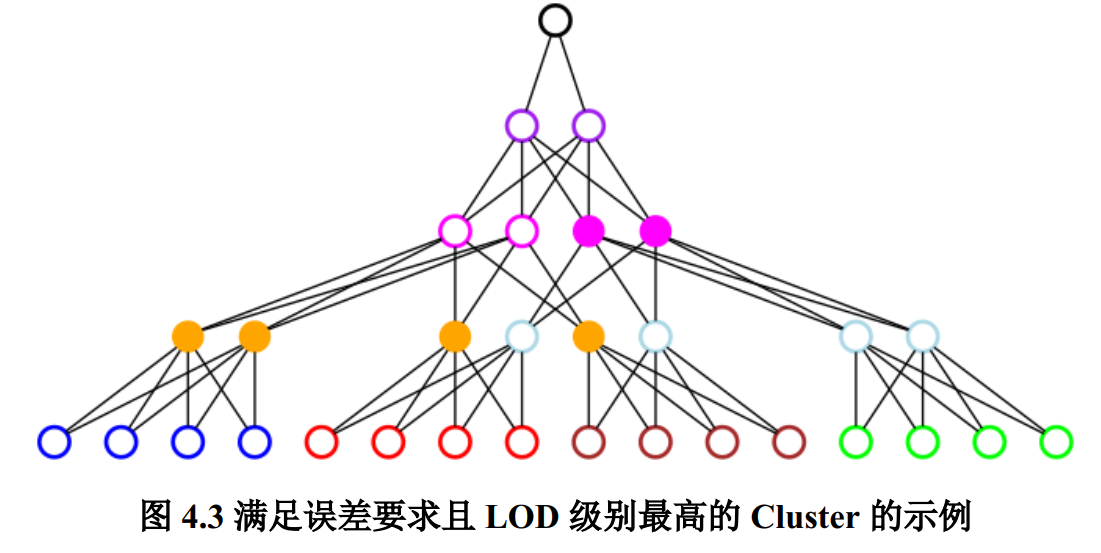
- 在满足最大误差阈值条件下,尽可能选择高层次LOD
- 使用简化误差作为LOD误差,同时根据cluster的包围球在屏幕上的投影,估计最大屏幕误差
- 既满足误差阈值又要尽可能高层次LOD,即其parent不满足误差要求,而其自身满足误差要求的cluster
self_error <= threshold && parent_error > threshold
- 算法性能要求,要能在GPU上并行地判断每个 cluster 是否被选中
- 在cluster中同时记录parent的误差与包围球,这样各个cluster之间就可以并行评估
一个cluster的所有parent的误差与包围球都应该一样,因此只需要记录一个。这是在生成DAG时保证的
- 在cluster中同时记录parent的误差与包围球,这样各个cluster之间就可以并行评估
在生成LOD时需要为每个cluster维护:
- LOD 误差:叶节点为0;LOD 包围球:对于叶节点而言,LOD包围球就是真实包围球,而父节点的LOD包围球是子节点的并集
- 真实包围球:用于cluster的遮挡剔除。父节点的包围球与LOD包围球是两个东西,LOD包围球比真实包围球大很多
- parent LOD 包围球
- parent LOD误差:{组内所有child cluster的lod误差,简化引入的误差}中的最大值
3.2 LOD 生成
3.2.1 cluster 生成
cluster 生成其实是对mesh中的三角形进行聚类,划分 N 个三角形为一个cluster,但为了最大化顶点重用,需要考虑到三角形之间的邻接关系。主要做法是,采用图思想,图的顶点表示一个三角形,边表示三角形之间的邻接关系。划分cluster过程就是对图划分子图过程,目标是 cluster的所有三角形尽可能的相邻。具体做法如下:
- 构建mesh的图结构。
3.3 基于层次细节的虚拟几何
虽然虚拟几何与虚拟纹理很相似,但需要特别注意以下不同之处:
- 虚拟几何在加载、卸载几何数据时,需要确保几何数据是完整的,即不会导致模型出现空缺。
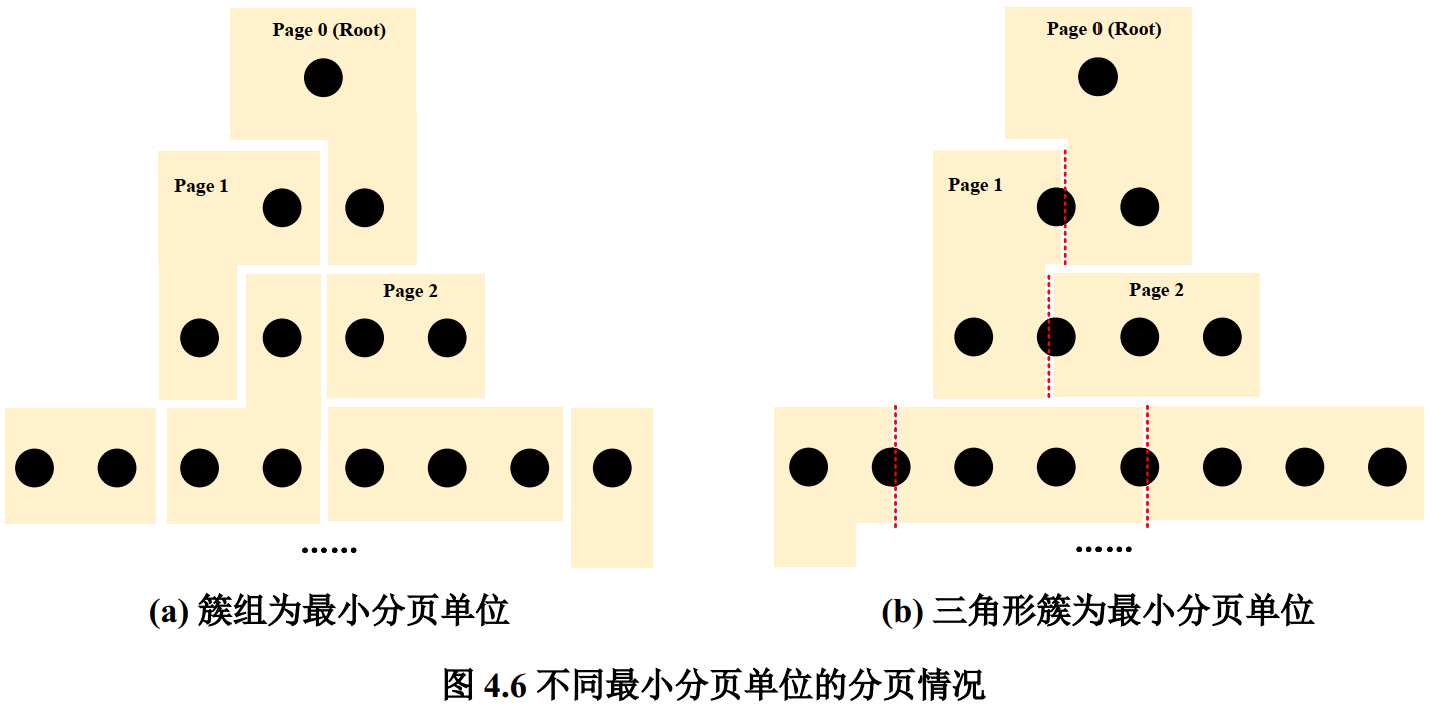
对于基于DAG的虚拟几何,则需要保证GPU上存在的一定是DAG的有效子图,即包含根节点的上层子图 - 几何是不固定大小的,如何组织几何数据?
- 如果以 cluster group 为单位,会导致page空间浪费。cluster group的cluster数量不固定,只是最多32个
- 以cluster为单位,将cluster group划分为多个连续子组,这样可以将一个cluster group存到不同的页中
会分配几个不参与加载、卸载的常驻页,用来存放根节点cluster以及更多顶部节点cluster。
3.3.1 页分配
3.3.1.1 cluster 排序
为了能够提高页内数据的空间局部性,需要对生成的cluster group(应该指层级选择到的)进行排序:
- LOD为第一优先级:从高到低
- 莫顿码为第二优先级:cluster group包围盒中心生成的莫顿码。空间邻近的cluster group在页内也相邻
此外,cluster group内的cluster使用其包围盒中心生成的莫顿码进行排序,空间邻近的cluster在页内也相邻
3.3.1.2 页分配算法
4 层级加速结构
当模型较大时,对 DAG 中的每个cluster都进行判断开销很高。而大场景渲染中,大部分模型都距相机较远,这种情况下,DAG中的大部分cluster都过于精细。
对每个cluster的 LOD 判断仅仅依赖其自身的误差和其parent的误差,因此我们可以使用cluster的局部数据构建BVH。
4.1 BVH 叶节点
BVH叶节点:使用group part作为叶节点。
- 由于一个cluster group共享parent数据,理论上BVH叶节点可以是cluster group。然而为了页分配,前面将cluster group切分为了更小单元,因此BVH使用group part作为叶节点。这里层级不区分LOD
4.2 BVH 存储的数据
BVH 需要存储的数据:
- parent的 LOD 误差和parent的 LOD 包围球。
建立 BVH 的目标是要剔除太过精细的 cluster,即其parent误差已经满足误差阈值 - 叶节点表示的group part包围盒
用于视锥剔除与遮挡剔除 - page request
某个叶节点通过LOD选择时,其几何数据可能未被加载到 GPU 上,因此需要向 CPU 请求对应的几何数据。叶节点应请求其所在cluster group的所有页,这些被请求页的信息也要存储在叶节点中。
4.3 BVH 结构
BVH 结构:使用数组表示的四叉 BVH
- 数组的每个元素为层次节点(Hierarchy_Node),其分为叶节点和非叶节点,两种节点采用相同的数据结构。
- 叶节点代表一个三角形簇组切片,通过叶节点能够访问到其对应的组切片中包含的三角形簇的实际数据
- 非叶节点则包含其子节点在层次结构缓冲中的索引,由于采用的是四叉 BVH,其子节点数目不超过 4
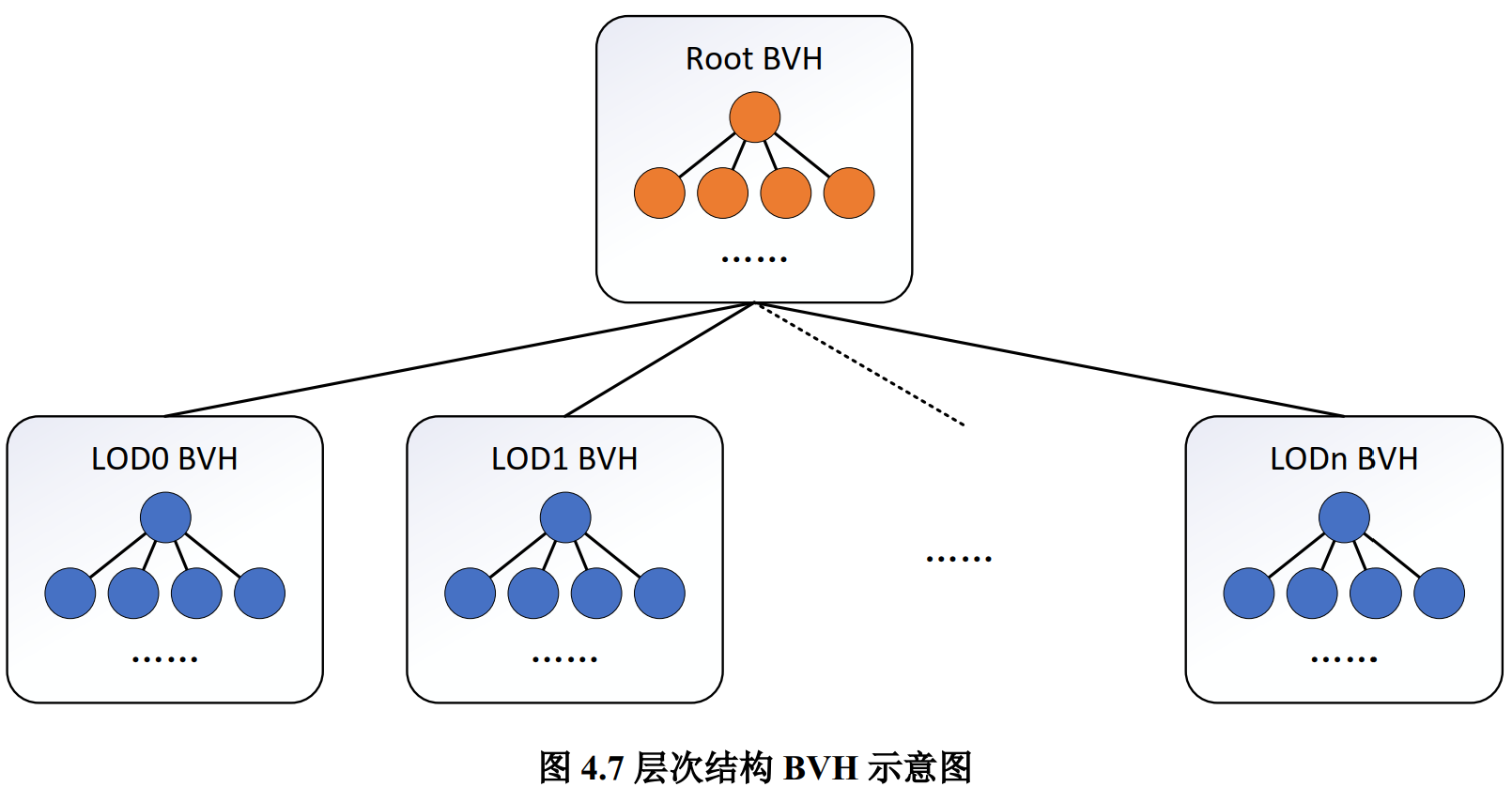
- 对每个 LOD 级别建立一棵 BVH,而后以每个 LOD 级别的 BVH 的根节点作为叶节点,建立一棵能够索引所有 LOD 级别的 BVH
- 单个LOD的BVH构建
- 每个 group part 作为一个叶节点
- 按照叶节点包围盒,使用轴排序分割算法,均匀分为4份,这样递归构建
- 包含所有LOD的BVH构建
- 各级LOD根节点的包围盒基本相同,因此这里将LOD BVH均匀分为四份,这样递归构建
- 单个LOD的BVH构建
5 多层次剔除
instance culling,hierarchy culling,cluster culling
4.1 Instance Culling
instance buffer 包含了每个 instance 相关信息,使用 instance id 索引,具体数据有:mesh_id, material_id, 以及一些变换
实例剔除使用compute shader实现,一个线程负责一个实例,使用模型包围盒加上实例变换执行:
- 执行视锥剔除
- 如果视锥剔除通过,再执行遮挡剔除
如果过程中,实例被剔除,则加入 occluded instance queue;如果剔除都通过,实例ID加入待处理层次节点队列
4.2 层次结构剔除
先在层次加速结构中执行视锥剔除、遮挡剔除以及剔除过于精细的cluster。下面是层次加速结构,本质上是两级加速结构,最外层是每个 LOD 层级BVH树组成的节点,内层每个LOD层级的BVH树的叶节点是连续clusters(cluster group的一部分)。整个加速结构使用包围盒管理。
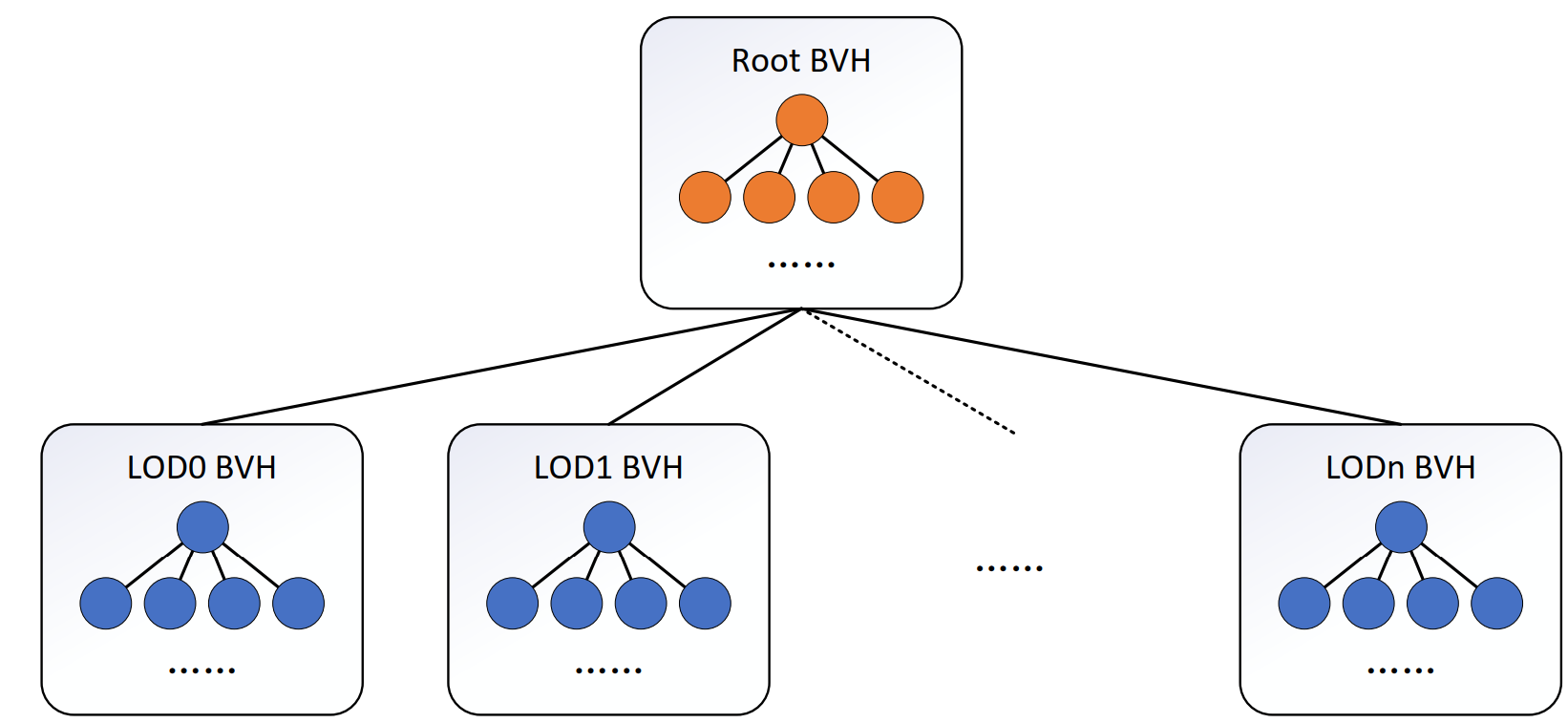
剔除过程包括:
- 对层次节点的包围盒执行视锥剔除
- 若视锥剔除通过,再执行 LOD 剔除,剔除掉过于精细的cluster,即 parent < threshold时,子节点可以全部剔除
- LOD剔除通过,再执行遮挡剔除
剔除通过的层次节点如果不是叶节点,则需要加入待处理队列,等待再次处理;若为叶节点,如果还未加载,则向叶节点写入page request,如果已加载则将叶节点的cluster数组加入待处理cluster队列。
剔除未通过的层次节点加入被遮挡待处理层次节点
4.3 cluster 剔除
对前面过程生成的待处理cluster队列中的每个cluster执行:
- 视锥剔除
- 遮挡剔除
剔除都通过放入可见cluster队列;否则放入被遮挡待处理cluster队列中
4.4 细节层级剔除
在进行 LOD 选择时,需要对 LOD 误差投影到屏幕上的最大投影误差进行估计,并根据投影误差与阈值误差的关系来决定是否满足误差要求。
4.4.1 投影误差计算
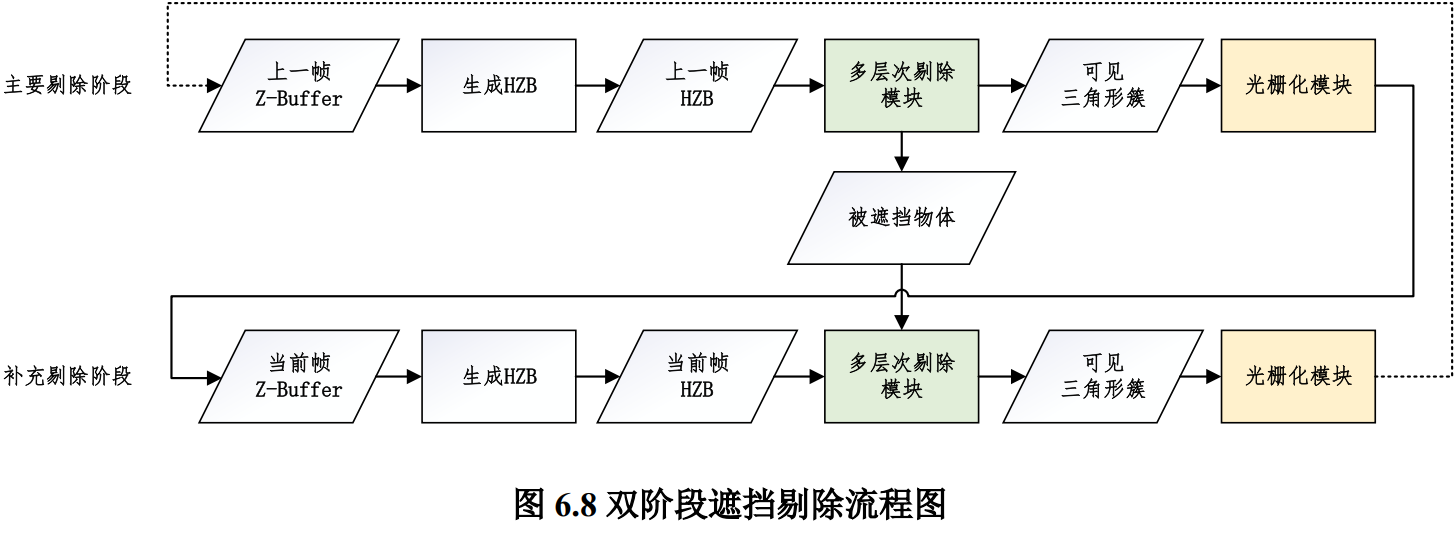
5.5 双阶段剔除
遮挡剔除使用深度缓存,而遮挡剔除发生在光栅化之前。在许多遮挡剔除算法中,会使用上一帧depth buffer,但由于相机/物体的移动,在上一帧中被遮挡的物体在当前帧未必会被遮挡,因此会造成一定的绘制错误。这里使用双阶段遮挡剔除:
- 主剔除阶段:
- 使用上一帧HZB、上一帧的相机与实例变换,通过剔除可以得到在上一帧可见cluster与被遮挡物体。
- 使用当前帧相机与实例变换对可见cluster光栅化得到当前帧部分 depth buffer
- 补充剔除阶段:
- 使用当前帧的部分 HZB与当前帧相机/实例变换,对主剔除阶段中记录的被遮挡实例、层次节点、cluster,使用当前帧HZB执行遮挡剔除。这样便得到了在上一帧中不可见,但在当前帧中可见的三角形簇。
- 注意:
- 在主剔除阶段的多层次剔除模块中,视锥剔除和 LOD 剔除正常进行,且遮挡剔除只有在上述两种剔除通过后才进行。
- 而在补充剔除阶段的多层次剔除模块中,由于只处理在上一帧中被遮挡的实例和三角形簇,因此无需再对它们进行视锥剔除和 LOD 剔除,只进行遮挡剔除即可。