移动端 TBDR
1 移动端限制
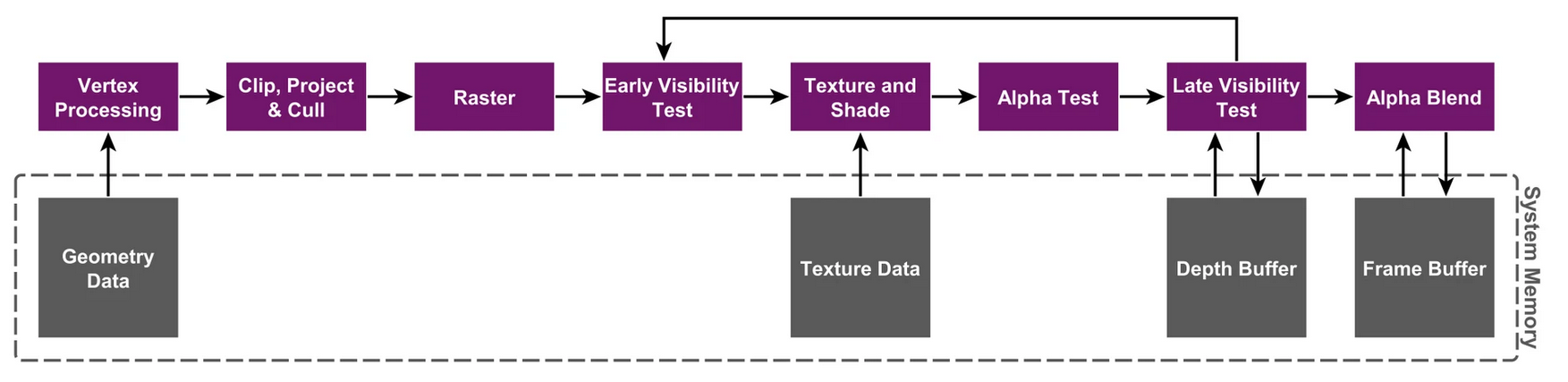
移动端相比于PC,具有很小的 cache、带宽很有限,带宽带来显著的功耗与发热问题。下图是PC采用的立即渲染 (IR) 架构下的图形管线,可以看到管线的多个阶段直接访问显存,这样的带宽开销对于移动端是不现实的。
2 TBR
移动端 GPU 架构倾向于最少化直接访问显存,将 framebuffer 划分为很多小块,使得每个小块可以被 SRAM(cache) 容纳,块的多少取决于硬件SRAM的大小。这样 GPU 就可以分批处理SRAM中的一块块framebuffer,一整块都完成后整体转移回 DRAM上。这种模式就叫做TBR(tile-based-rendering)。TBR 架构下的图形管线如下图,步骤如下
- 缓存所有绘制指令直到最后才开始进行真正绘制
- 首先对所有图元执行VS,把相关的所有绘制数据保存起来
- 计算每个tile都包含哪些图元
- 开始绘制一个tile
- 依次绘制tile中的每个图元
- 把绘制好的tile拷贝到framebuffer对应的位置上
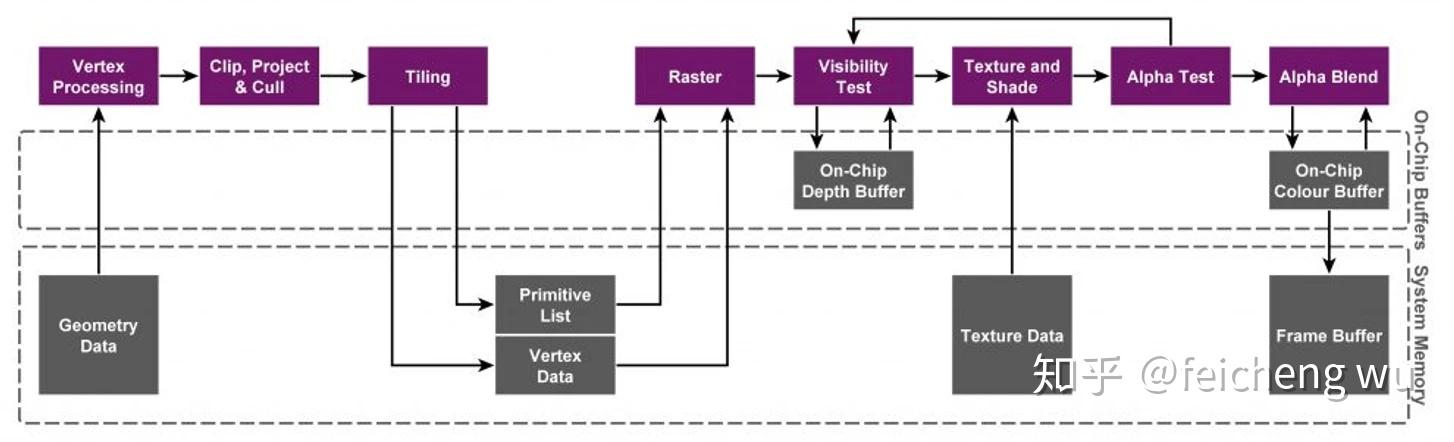
TBR 将光栅化过程延迟到tile内所有图元都处理完成才开始,而不是 IMR 那种以图元为单位 (其实是primitive subgroup)。可以看到上图中 On-Chip Depth Buffer、On-Chip Color Buffer 是cache中framebuffer的tile暂存位置。
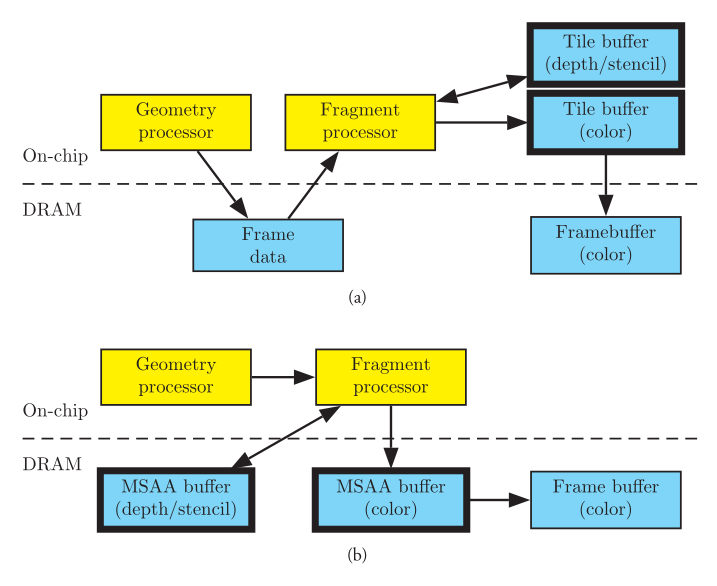
可以看出,在 TBR 架构下,移动端 GPU 接收来自CPU端的绘制指令后的绘制行为完全被改变了。TBR 架构下,不能够来一个绘制指令就执行一个,否则 GPU 会在每一个 draw call 中来回搬运 tile,这样效率很低。因此 TBR 一般的实现策略是对于 CPU 提交的 command buffer,只对它们做顶点处理,然后暂存 vs 的计算结果回显存,等不得不刷新整个 FrameBuffer 的时候,才真正为这批绘制做光栅化,做 tile-based-rendering。如下图 TBR 与 IR 之间对比,可以看到 TBR 管线在Pixel Shader 之前多了一个步骤,即vs和gs处理后的数据(这里叫做FrameData)被暂时保存下来排好队。后面再对 framebuffer 划分 tile,然后对每个 tile,绘制所有影响这个tile的图元 (步骤 4,5,6)。
那么何时不得不刷新整个 FrameBuffer: Swap Back and Front Buffer, glflush, glfinish, glreadpixels, glcopytexiamge, glbitframebuffer, queryingocclusion, unbind the framebuffer。总之就是通知GPU现在就需要用到FrameBuffer上数据的时候。
3 TBDR
TBDR 是基于 TBR 的改进,二者关键区别:
- TBR: VS -> Defer -> RS -> PS
Defer 是指几何处理结果暂存 Frame data,延迟光栅化 - TBDR: VS -> Defer -> RS -> Defer -> PS
第一个 Defer 与 TBR 相同,而增加的第二个 Defer 则是延迟 PS 的执行,延迟到 tile 所有图元都处理完,消除 overdraw
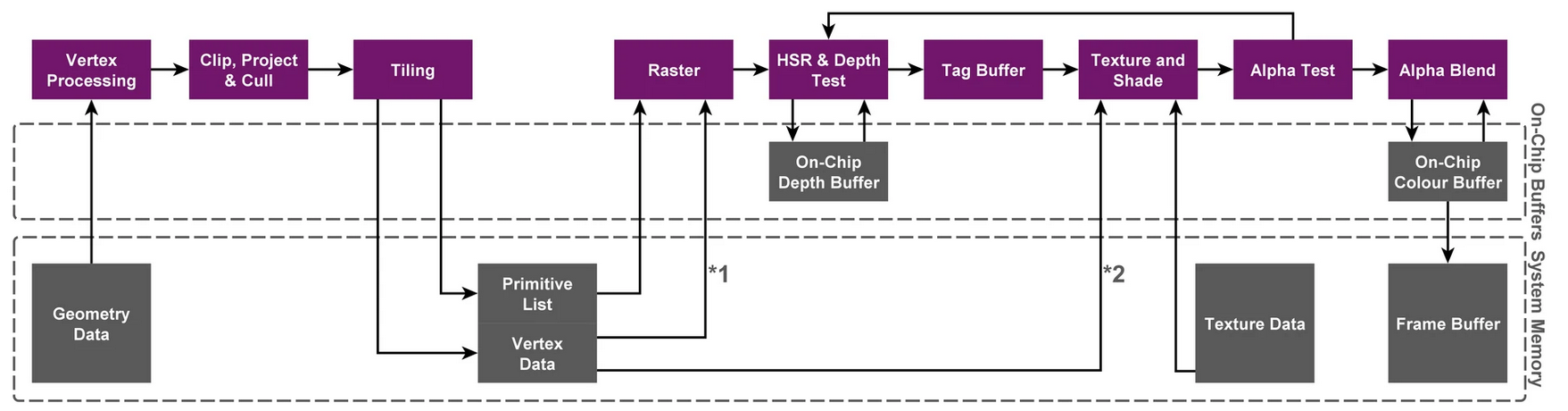
下图为 TBDR 下的图形管线,相比于 TBR 关键多了 HSR 技术
3.1 HSR (Hidden Surface Removal)
在介绍 HSR 之前,先简要回顾 early-z 技术。简单来说,就是将 depth test 提前到 PS 之前,只有通过深度测试的像素才会执行 PS。early-z 带来的好处就是减少了 overdraw,即前面绘制的像素被后面绘制的像素所覆盖。但 early-z 无法完全避免 overdraw 问题,因为绘制顺序无法严格做到从近到远。
HSR在硬件上实现了零Overdraw的优化,其主要原理是:
- 当 tile 的一个像素通过了 early-z 准备执行PS之前,先不画,只标记该像素所属图元。(这就是第二个 Defer)
- 等到这个 tile 上所有图元都处理完成,再真正开始为 tile 像素执行 PS。此时,每个像素都是最后通过 early-z 的图元像素点。同时由于TBR的机制,tile 中所有图元的相关信息都在 cache 上,可以极小代价去获得。最终零Overdraw。
3.2 HSR 的局限性
与 early-z 类似,HSR 在 alpha test 或 alpha blend 同样有局限性,会中断 Defer 流程,
- alpha test 是根据 PS 结果来选择是否丢弃(discard)当前像素,而HSR的提前深度测试位于 alpha test 之前。如果像素深度测试通过而又被 alpha test 丢弃,会导致深度与color不匹配。early depth test 会同时写深度
当HSR处理不透明物体时,突然来了一个alpha test图元,那么为了保证渲染结果正确,HSR就必须要终止当前的Defer。先把已标记好的像素都绘制出来,再进行后面的绘制。这显然严重影响了渲染的效率,也是为什么官方文档特意提到尽量避免alpha test的原因。 - alpha blend 是绘制半透明物体使用的,这里会关闭深度写,只有深度测试。相对应的alpha blend同样也要中断HSR的Defer,强制开始绘制,但是比alpha test好那么一点点的是他不影响后续图元并行地继续开始进行HSR处理
4 移动设备渲染通用优化建议
移动端GPU相比于PC的带宽开销成本很高,带宽开销应该是关注重点,针对带宽的优化:
- 贴图压缩
- 尽量开启mipmap (除了UI贴图外),这会增加总的内存开销,但会减少实际使用贴图内存,即内存开销和带宽开销的权衡
- 随机纹理寻址相对于相邻纹理寻址有显著开销
- 3D texture sampling 有显著开销。
- trilinear 与 anisotropic 相比于 bilinear 有显著开销
- 使用 LUT 可能是负优化。
- 贴图通道能合并就合并,减少贴图采样次数
- 不使用Framebuffer的时候clear或者discard
前面说到frame data会一直积攒下来直到等到一些必须要绘制到framebuffer上的时候,而glclear这种操作是可以把当前的frame data清空的,这样就会节省很多不必要的绘制。 - 在每帧渲染之前尽量clear
对于pc端而言,每帧渲染都会覆盖之前结果,因此不clear也能保证结果正确。但对于移动端GPU,这样会带来额外开销。因为如果不clear,每个tile在初始化时都要从显存的frame buffer的对应tile数据完整拷贝过来,而clear操作就表明不再需要之前的数据,因此避免了这种从显存的拷贝。 - 不要在一帧里面频繁的切换framebuffer
TBDR 架构只在不得不绘制的时候才渲染frame buffer,而每一次bind/unbind都需要对整个framebuffer的一次立即绘制。 - 避免大量的draw call和顶点量
TBR 渲染时,在几何处理后会存储frame data队列,这个frame data数据会随着draw call、顶点量而增大,顶点量占大头,甚至在一些情况增大到内存放不下的情况,而需要暂时移动到别处,这种情况对frame data的访问速度就奇慢无比了。 - 避免GPU上的copy-on-write
因为 TBDR 的渲染是延迟的,想象这样一种情况,当前帧内对一个mesh做顶点动画,传递给GPU绘制,然后后面又改变了它的顶点动画,又提交给GPU。这样前面一个VB绑定在GPU上还没有被处理,处于frame data队列状态。同一个VB(改变过的)又要过来了,这时GPU会对这个VB做一个新的拷贝,以存储VB的多份不同的数据。显然这又增加了frame data的存储,会触发上面11的瓶颈。所以千万不要在同一帧内多次改变提交给GPU的资源,这会迅速把frame data撑大到装不下的状态。
5 Profile
https://zhuanlan.zhihu.com/p/560738175
https://zhuanlan.zhihu.com/p/718875386
https://gdcvault.com/play/1034830/Innovation-Unleashed-High-Performance-UE5