Device Removed
1 Summary
Device Removed 发生于 GPU crash、TDR (Timeout Detection and Recovery),本文介绍一些用于debug这种情况的工具。
2 Device Removed
GPU crash 的发生过程:
- OS 调度buffer至GPU执行
- 执行期间 GPU 发生故障(或者buffer处理超时)
- GPU调度器无响应持续X秒(默认2秒)
- OS 触发蓝屏检查,内核态驱动程序 (KMP) 尝试重置引擎/适配器
- 后续引发 device removed 或者更糟
检测 GPU Crash:
- 基于图形API返回的error code,例如 (DirectX错误代码DXGI_ERROR_DEVICE_REMOVED)
- 崩溃发生于最近N帧GPU命令队列执行期间
- 此时的CPU调用栈很可能是无关线索

3 debug 工具
3.1 Aftermath
NVIDIA 推出的事后崩溃debug工具,用于分析GPU crash,可集成至游戏中,捕获真实运行场景中的崩溃。
3.1.1 GPU 崩溃原因
(1)TIME-OUT
- 驱动引起的超时,例如 unrecoverable fault
- 长时间任务执行,例如 shader 中的死循环
- 不正确同步,例如无信号触发的等待
(2)FAULT
- page fault,如 non-resident read,显存页未加载到GPU,需DMA调页
- invalid page access,例如以texture方式读取 buffer
- push buffer fault,错误格式指令
- graphics exception,未对齐的常数缓冲区视图 (CBV)
在 device removed之后调用以下接口来查询device status,可能的状态有:
- Transition:Unknown, Active, Stopped, Reset
- Timeout
- Faults: OutOfMemory, PageFault, DmaFault
1 | |
3.1.2 资源追踪
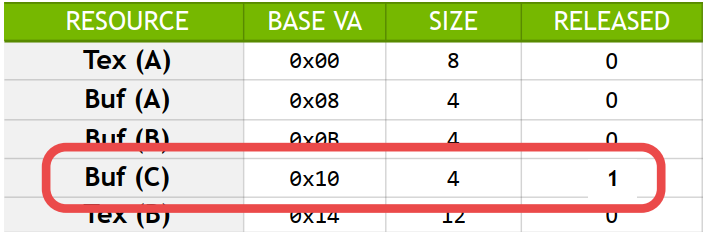
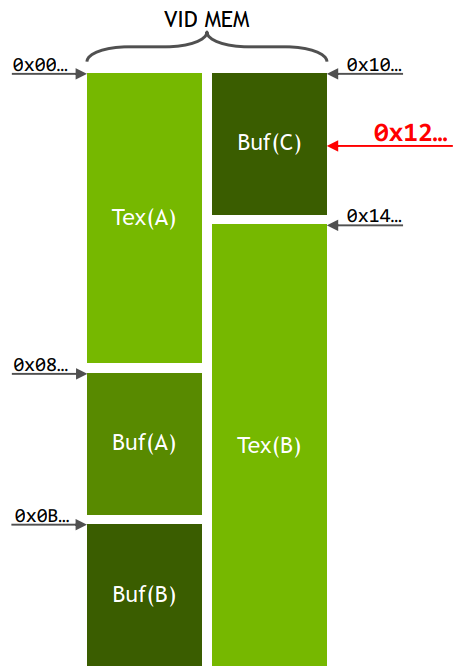
资源追踪通过维护资源与其VA的对应表,使页错误可被诊断,当发生页错误时,可锁定引发异常的具体资源对象,而不是报错只有一个虚拟地址。
例如:
- 释放或逐出 ‘Buf(C)’
- 在shader中访问 ‘Buf(C)’
- 在 0x12 地址上发生页错误
- 最后占用该地址的是 ‘Buf(C)’
当发生页错误与device removed之后,调用
1 | |
使用以下接口来关联应用层与驱动层资源
1 | |
3.1.3 Checkpoint
检查点是为了精确定位GPU crash 在命令流中的位置。示例流程:
- CPU端在命令流中插入用户自定义标记
- GPU执行到每个检查点时触发信号
- 最后到达的标记即为GPU崩溃发生位置
插入一个checkpoint
1 | |
当 device removed 被检测到时
1 | |
3.1.4 用处?
aftermath提供的以上机制并非告诉你crash的具体原因,而是提供线索:
- 检查点机制无法告知引发GPU crash的具体 workload,仅是标记GPU最后完成处理的指令点
- 资源追踪技术不能定位导致崩溃的具体资源,而是与故障虚拟地址存在映射交集的关联资源
GPU crash的debug过程:
- 收集给定复现案例的所有崩溃报告数据
- 寻找崩溃间的共性关联,例如相同着色器、共享资源。注意:着色器存在大量代码复用!(需检查汇编代码…)
- 对共性因素分而治之
Reference
Device Removed
http://example.com/2025/05/24/Rendering Blogs/Profile/Device Removed/